Pytorch 入门(2)
前言
学习尚硅谷的 NLP 教程。
霹雳吧拉Wz:
- 2.1 Lenet 50分钟
- 3.1+3.2 AlexNet 47分钟
- 4.1+4.2 VGG 32分钟
- 5.1+5.2 GoogleNet 45分钟
- 6.1+6.2 ResNet 74分钟
- 7.1+7.2 MobileNet 57分钟
- Pytorch 查看中间层特征矩阵以及卷积核参数 22分钟
以上5.45小时
技术演进历史
90 年代,随着计算能力的提升和语料资源的积累,统计方法逐渐成为主流。通过对大量文本数据进行概率建模,系统能够“学习”语言中的模式和规律。典型方法包括 n-gram 模型、隐马尔可夫模型(HMM)和最大熵模型。
进入 21 世纪,NLP 技术逐步引入传统机器学习方法,如逻辑回归、支持向量机 (SVM)、决策树、条件随机场(CRF)等。这些方法在命名实体识别、文本分类等任务上表现出色。在此阶段,特征工程成为关键环节,研究者需要设计大量手工特征来提升模型性能。
自2010年开始,深度学习在NLP中迅速崛起。基于神经网络的模型,比如 RNN、LSTM、GRU等,取代了传统手工特征工程,能够从海量数据中自动提取语义表示。随后,Transformer 架构的提出极大提升了语言理解与生成的能力,深度学习不仅在精度上实现突破,也推动了预训练语言模型(如GPT、BERT等)和迁移学习的发展,使 NLP 技术更通用、更强大。
安装所需依赖
该课程使用的 Python 版本是 3.12。安装所需依赖有:
pytorch:深度学习框架,主要用于模型的构建、训练与推理。jieba:高效的中文分词工具,用于对原始中文文本进行分词预处理。gensim:用于训练词向量模型(如 Word2Vec、FastText),提升模型对词语语义关系的理解。可以使用公开的中文词向量transformers:由 Hugging Face 提供的预训练模型库,用于加载和微调 BERT 等主流模型。datasets:Hugging Face 提供的数据处理库,用于高效加载和预处理大规模数据集。tensorboard:可视化工具,用于展示训练过程中的损失函数、准确率等指标变化。tqdm:用于显示进度条,帮助实时监控训练与数据处理的进度。Jupyter Notebook:交互式开发环境,用于编写、测试和可视化模型代码与实验过程。scikit-learn:机器学习工具。可以用来划分数据集。
文本表示方法
文本表示是将自然语言转化为计算机能够理解的数值形式。
早期的文本表示方法(如词袋模型)通常将整段文本编码为一个向量。这类方法实现简单、计算高效,但存在明显的局限性——表达语序和上下文语义的能力较弱。
因此,现代 NLP 技术逐渐引入更加精细和表达力更强的文本表示方法,以更有效地建模语言的结构和含义:
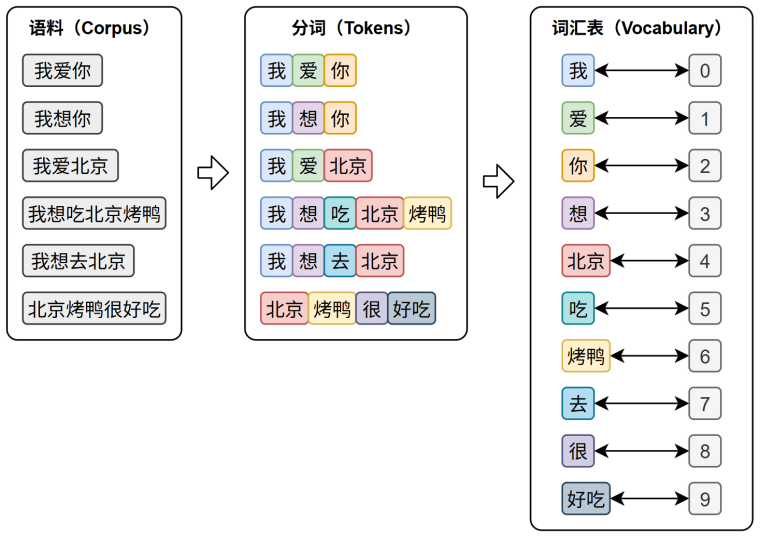
- 分词(Tokenization)是将原始文本切分为若干具有独立语义的最小单元,即
token的过程,是所有 NLP 任务的起点 - 词表(Vocabulary)是由语料库构建出的、包含模型可识别 token 的集合。词表中每个 token 都分配有唯一的
ID,并支持 token 与 ID 之间的双向映射 - 词向量:在训练或预测过程中,模型会首先对输入文本进行分词,再通过词表将每个 token 映射为其对应的 ID。接着,这些 ID 会被输入嵌入层,转换为低维稠密的向量表示,也就是词向量。ID 可以用 one-hot 向量表示,通过与词表进行矩阵乘法,抽出对应的词向量
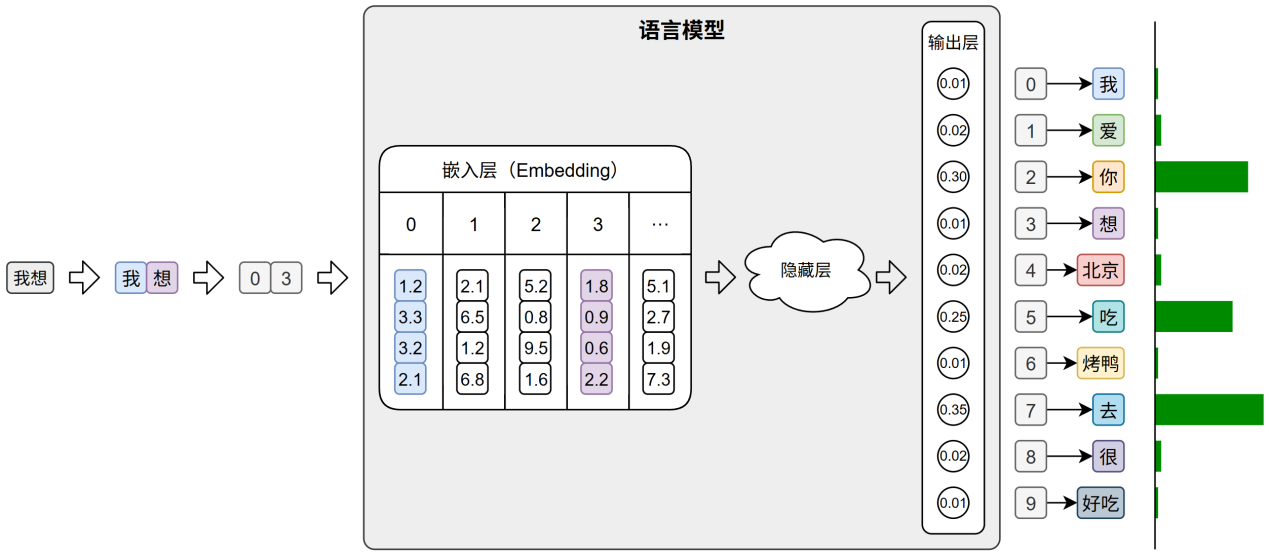
在文本生成任务中,模型的输出层会针对词表中的每个 token 生成一个概率分布,表示其作为下一个词的可能性。系统通常选取具有最大概率的ID,并通过词表查找对应的 token,从而逐步生成最终的输出文本。下图中输入文本为“我想”,该文本的下一个词概率明显较大的有“你”、“吃”、“去”,即“我想你”、“我想吃”、“我想去”。
这一过程很像是在查字典,拿到一个句子,里面有一些不认识的单词,识别出陌生单词的行为就是分词。通过单词查询字典对应条目所在的页数,页数即为 ID。通过页码查看该单词详细的释义,释义即是词向量。字典的解释总是比单词要多上许多内容,模型通过这些内容进而更好的理解陌生单词,从而把握整句话的含义。
词向量有静态与动态之分。静态词向量只为每个词分配一个固定的向量表示,不论它在句中出现的语境如何。然而,语言的表达极其灵活,一个词在不同上下文中可能有完全不同的含义。这就推动了上下文相关的词表示的发展。上下文相关词表示(Contextual Word Representations),是指词语的向量表示会根据它所在的句子上下文动态变化,从而更好地捕捉其语义。一个具有代表性的模型是——ELMo。
英文分词
按照分词粒度的大小,可分为词级(Word-Level)分词、字符级(Character‑Level)分词和子词级(Subword‑Level)分词。
英语的词级分词按照空格和标点分隔词语,这种分词虽然便于理解和实现,但在实际应用中容易出现 OOV(Out‑Of‑Vocabulary)问题。所谓 OOV,是指在模型使用阶段,输入文本中出现了不在预先构建词表中的词语,常见的有网络热词、专有名词、复合词及拼写变体等。由于模型无法识别这些词,通常会将其统一替换为特殊标记,如 <UNK>(Unknown Token),从而导致语义信息的丢失,影响模型的理解与预测能力。
字符级分词是以单个字符为最小单位进行分词的方法,文本中的每一个字母、数字、标点甚至空格,都会被视作一个独立的 token。在这种分词方式下,词表仅由所有可能出现的字符组成,因此词表规模非常小,覆盖率极高,几乎不存在 OOV问题。然而,由于单个字符本身语义信息极弱,模型必须依赖更长的上下文来推断词义和结构,这显著增加了建模难度和训练成本。此外,输入序列也会变得更长,影响模型效率。
子词级分词是一种介于词级分词与字符级分词之间的分词方法,它将词语切分为更小的单元——子词(subword),例如词根、前缀、后缀或常见词片段。与词级分词相比,子词分词可以显著缓解OOV问题;与字符级分词相比,它能更好地保留一定的语义结构。
中文分词
类似英文分词,中文分词也能按照三个等级进行划分:
- 字符级分词:一个汉字作为一个 token
- 词级分词:一个词语作为一个 token。由于中文词语不像英文那样可以用空格进行区分,所以需要依赖词典、规则或模型来识别词语边界
- 子词级分词:以汉字为基本单位,通过学习语料中高频的字组合(如“自然”、“语言”、“处理”),自动构建子词词表
中文分词工具,按照实现方式分为如下两类:
- 一类是基于词典或模型的传统方法,主要以“词”为单位进行切分。比如 jieba、HanLP
- 另一类是基于子词建模算法(如BPE)的方式,从数据中自动学习高频字组合,构建子词词表。比如 Hugging Face Tokenizer、SentencePiece、tiktoken
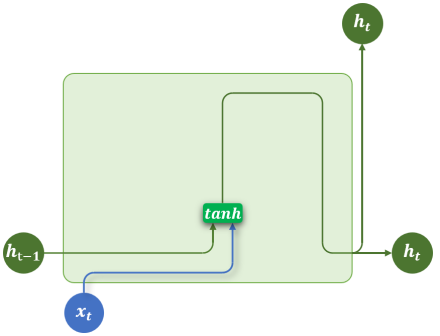
RNN
RNN(循环神经网络)的核心结构是一个具有循环连接的隐藏层,它以时间步(time step)为单位,依次处理输入序列中的每个 token。
在每个时间步,RNN 接收当前 token 的向量和上一个时间步的隐藏状态(即隐藏层的输出),计算并生成新的隐藏状态,并将其传递到下一时间步。其公式为:
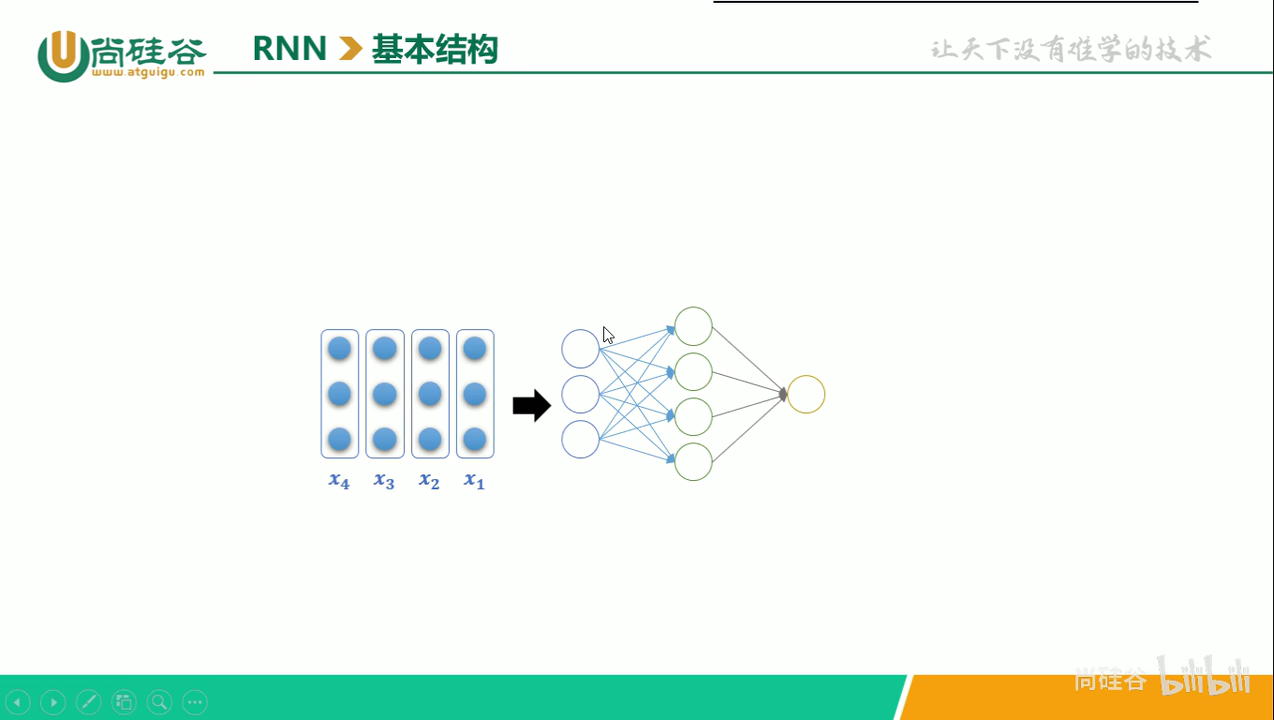
seq_len为4,即从 到 ,是序列长度input_size为3,即每个 的长度,是每个时间步输入特征的维度(词向量维度)hidden_size为4,即图中右侧的四个圆。
单层结构
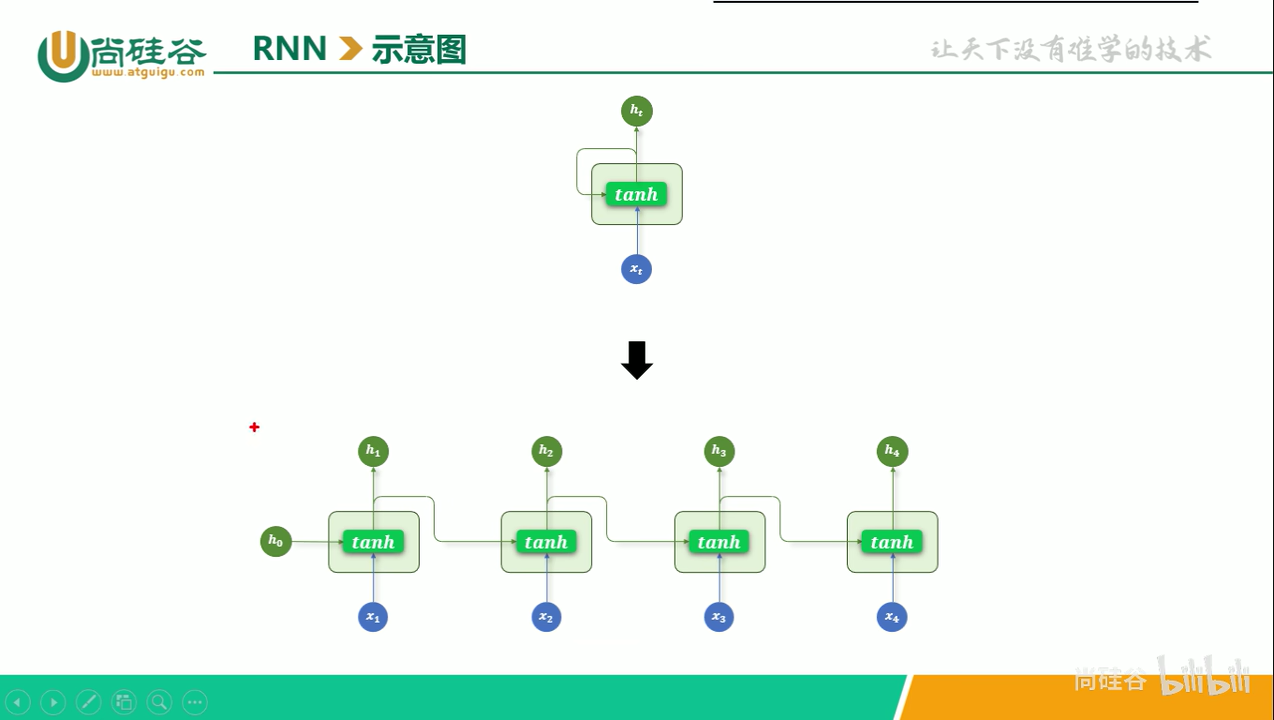
注意,图中单层结构 RNN 展开后有4个包含激活函数 tanh 的层,但实际上他们是共用一个层。
多层结构
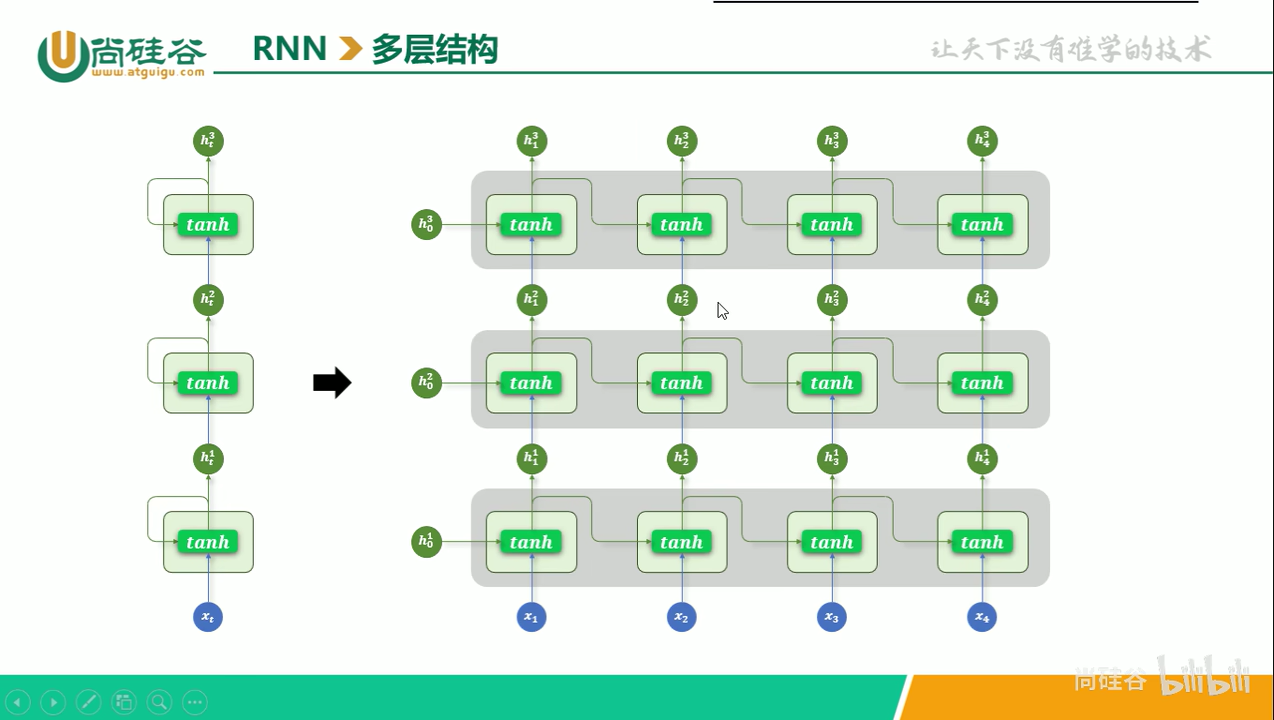
图中形如 的符号,其下标表示时间步,上标表示 RNN 的层数。如果把图中右侧的展开图视为一个原点在左下角的平面坐标系,那么坐标系的 x 轴是时间步,y 轴是层数。
双向结构
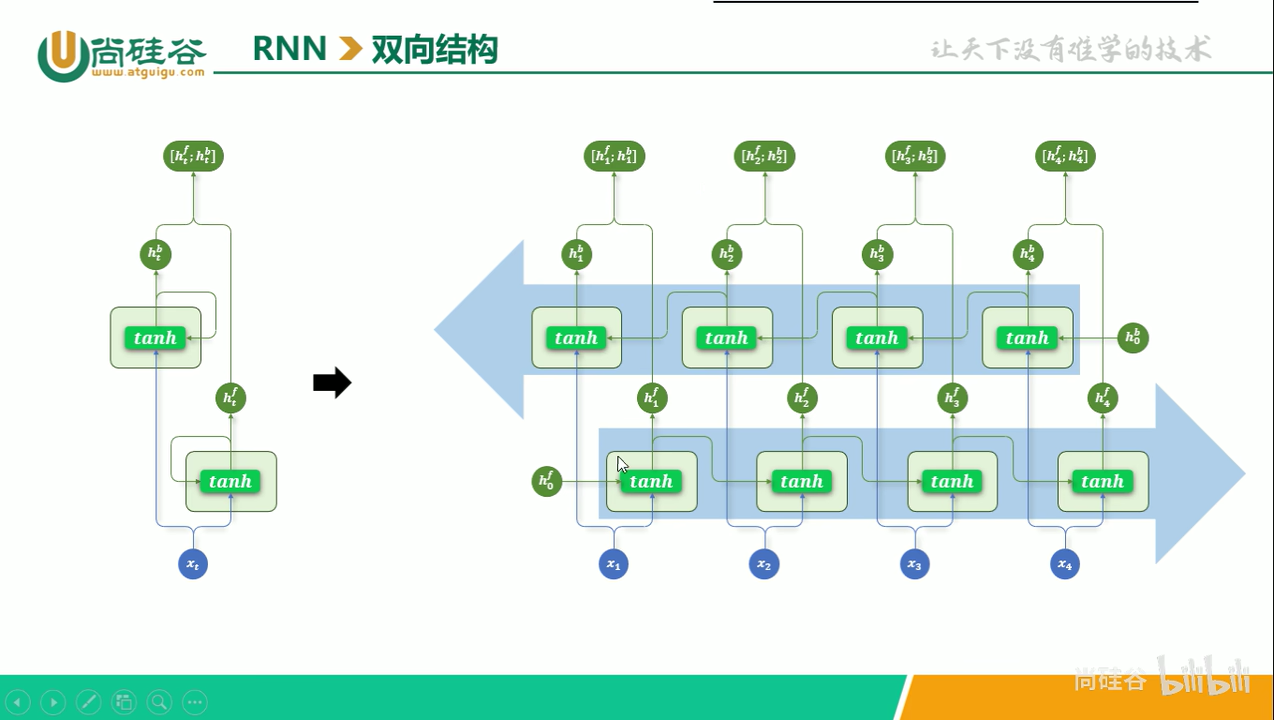
前面提到的 RNN 都是单向结构的,在每个时间步只输出一个隐藏状态,该状态仅包含来自上文的信息。为了充分利用当前词之后的下文,即利用上下文内容,人们设计了双向结构的 RNN,反映在上图中就是,有两个方向的箭头:一个从左侧进入激活函数 tanh,一个从右侧进入激活函数 tanh。不过两个 tanh 所在的层不是同一个,出于训练效率的考虑,正向和逆向的两个层应该并行训练。
最后,正向 RNN 和 逆向 RNN 通过简单的拼接(concat)作为下一层的输入,如果 RNN 是多层结构。
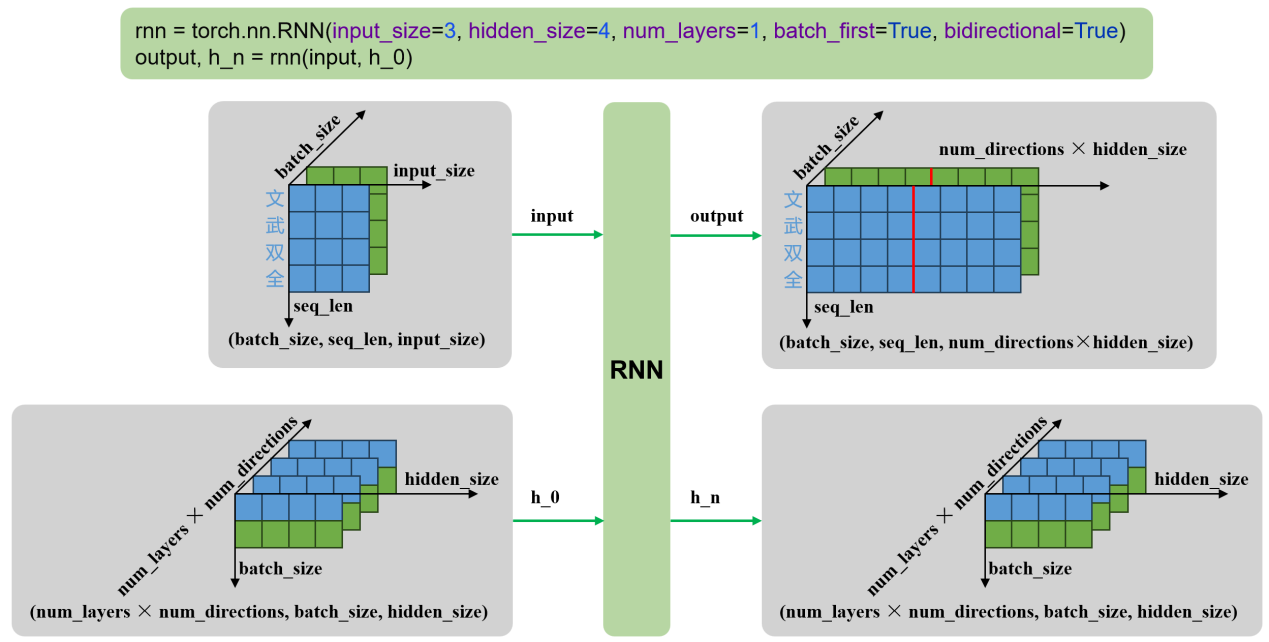
RNN 实践
数据集处理
数据集下载地址:https://huggingface.co/datasets/Jax-dan/HundredCV-Chat。也可以从 huggingface 的镜像地址下载:https://hf-mirror.com/datasets/Jax-dan/HundredCV-Chat。
数据集文件的格式为 .jsonl,jsonl 文件的每一行可以看作一个 json 文件,下面代码来自数据集文件的第一行。本任务中只需用到数据集中的对话文本。
{
"topic": "校园生活分享",
"user1": "李欣怡",
"user2": "杨欢",
"dialog": [
"user1:杨欢,最近校园里有什么新鲜事吗?",
"user2:嗨,李欣怡!我们学校刚刚举办了一次科技节,很多学生展示了他们的发明。",
"user1:听起来好有趣!我这边的学校正在筹备一场文化节,主要是推广传统文化。",
"user2:文化节听起来也很棒。你们会做哪些活动呢?",
"user1:我们打算办个书法展和传统服饰秀,还会请来一些老师教大家制作传统小吃。",
"user2:真不错!我们科技节上有同学展示了一款智能垃圾分类箱,挺受欢迎的。",
"user1:这创意真好。我们也应该多关注环保问题,比如组织一次清洁校园的活动。",
"user2:对,我也觉得这样做很有意义。你们学校有类似的社团或小组吗?",
"user1:有的,我们有一个志愿者服务队,经常会组织这样的活动。",
"user2:那真是太好了!你平时是怎么平衡学业和这些课外活动的呢?",
"user1:我会合理安排时间,把学习放在第一位,然后是重要的活动。你觉得呢?",
"user2:我也是这样做的。我觉得找到自己的兴趣点很重要,这样才能更有动力去做好每一件事。",
"user1:完全同意!对了,你参加过模拟联合国社团吗?",
"user2:参加过,挺有意思的。你呢?有没有类似的经历?",
"user1:有啊!我还当过中国代表团的代表,提出了很多关于可持续发展的建议。",
"user2:真厉害!你在这些活动中一定学到了不少东西吧?",
"user1:当然了,不仅增长见识还锻炼了我的团队合作能力。你也一样吧?",
"user2:是的,我也从中受益匪浅,特别是编程能力和解决问题的能力得到了提升。",
"user1:希望以后我们能有更多机会一起交流学习经验。",
"user2:绝对同意!我们可以互相分享更多的校园活动信息和心得。"
]
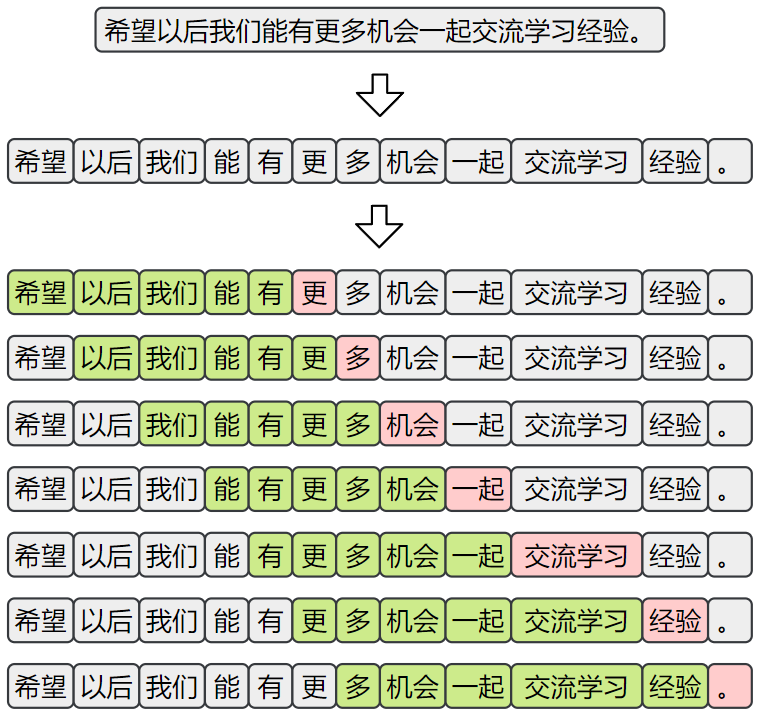
}为了构造适用于“下一词预测”任务的训练样本,首先需要对原始语料进行分词。随后,采用滑动窗口的方式,从分词后的序列中提取连续的上下文片段,并以每个窗口的下一个词作为预测目标,构成输入-输出对,如下图所示:
模型结构设计
本任务采用基于 RNN 的语言模型结构来实现“下一词预测”功能。模型整体由以下三个主要部分组成:
- 嵌入层。将输入的词或字索引映射为稠密向量表示,便于后续神经网络处理。
- RNN。用于建模输入序列的上下文信息,输出最后一个时间步的隐藏状态作为上下文表示。
- 输出层。这里是线性层,将隐藏状态映射到词表大小的维度,生成对下一个词的概率预测。
训练方案
- 损失函数选择 CrossEntropyLoss。预测下一词功能,可以看作多分类问题
- 优化器选择 Adam
项目结构
input_method
├── data # 数据目录
│ ├── processed # 预处理后的数据
│ └── raw # 原始数据
├── logs # 训练日志
├── models # 保存训练好的模型参数
└── src # 源码目录
├── config.py # 超参数配置
├── dataset.py # 自定义Dataset
├── evaluate.py # 模型评估脚本,存放评价指标
├── model.py # 模型结构定义
├── predict.py # 模型推理脚本
├── process.py # 数据预处理脚本
├── tokenizer.py # 自定义分词器
└── train.py # 模型训练脚本import os
import pandas as pd
CURRENT_DIR = os.path.dirname(os.path.abspath(__file__))
def process():
print("开始处理数据")
# 1.读取文件
jsonl_path = os.path.join(CURRENT_DIR, "../data/raw/synthesized_.jsonl")
df = pd.read_json(jsonl_path, lines=True, orient="records")
print(df.head())
print("数据处理完成")
if __name__ == "__main__":
process()词表基于训练集构建,
需要额外添加一个 <UNK> ,
词表必须有序。
词表保存在 models 目录下,和模型参数放一个地方。
词表中每一行是一个 ID,ID 之间用换行符分隔,可以视为一个大字符串,字符之间用 \n 分割。
构建词表时,最费时的阶段是给句子分词,可以用 tqdm 显示进度条,以及用 df_sample = df.sample(frac=0.1) 抽样,抽取十分之一的数据。
model.pylast_hidden_state = output[:, -1, :] 省略掉第二个维度,因为该维度的大小为1
with open(config.MODEL_PATH / "vocab.txt", "r", encoding="utf-8") as f:
vocab_list = f.readlines()
print(vocab_list[:5])['<unk>\n', '交通管理\n', '福音\n', 'RFM\n', '钉\n']tensorboard 可以实时检测训练过程。
通过设置层级目录,tensorboard 可以在一张图上显示多次实验的结果,用来进行比较
input_tensor = torch.tensor([indexs], dtype=torch.long).to(device) 这里的 [] 用于增加一个维度,使张量形状从 [seq_len] 变为 [1, seqlen]
预测脚本的模拟应用:
def predict(text):
# 1. 设备
device = "cuda" if torch.cuda.is_available() else "cpu"
# 2. 词表
with open(config.MODEL_PATH / "vocab.txt", "r", encoding="utf-8") as f:
vocab_list = [line.strip("\n") for line in f.readlines()]
word2index = {word: index for index, word in enumerate(vocab_list)}
index2word = {index: word for index, word in enumerate(vocab_list)}
# 3. 模型
model = InputMethodModel(vocab_size=len(vocab_list)).to(device)
# 4. 处理输入
tokens = jieba.lcut(text)
indexs = [word2index.get(token, 0) for token in tokens]
# input_tensor = torch.tensor(indexs, dtype=torch.long).unsqueeze(0)
input_tensor = torch.tensor([indexs], dtype=torch.long).to(device)
# 5. 预测逻辑
model.eval()
with torch.no_grad():
output = model(input_tensor)
# output.shape: [batch_size, vocab_size]
top5_indexes = torch.topk(output, k=5).indices
# top5_indexes.shape: [batch_size, 5]
top5_indexes_list = top5_indexes.tolist()
top5_tokens = [index2word.get(index) for index in top5_indexes_list[0]]
return top5_tokens
if __name__ == "__main__":
top5_tokens = predict("我们团队")
print(top5_tokens)evaluate 函数有调用 predict.py 中 predict_batch 函数,后者里面已经有 model.eval() 和 with torch.no_grad(): ,所以 evaluate 函数开头两行不用写这两句。
target = target.tolist() :该评估脚本不需要计算损失,因此 target 也不用放到 gpu 上。
pytorch 中 topk 默认按从大到小排序
将词表操作相关的代码抽取出来,放到 tokenizer.py 中。
对象 JiebaTokenizer:
属性:
vocab_list:list[str]词表列表vocab_size:int词表大小word2index:dict[str, int]word 到 index 的映射index2word:dict[int, str]index 到 word 的映射unk_token:str未登录词,比如<unk> <begin> <end>,这是个类属性unk_token_index:int未登录词 index
方法:
@staticmethod
def tokenize(sentence: Any) -> list[str]
"""
分词
将 jieba.lcut() 封装到列表中
:parma sentence: 句子
:return: token列表
"""
@classmethod
def build_vocab(cls,
sentence: list[str],
vocab_file: Any)
"""
构建并保存词表
:parma sentence: 句子
:parma vocab_file: 词表文件路径
"""
@classmethod
def from_vocab(cls, vocab_file: Any) -> JiebaTokenizer
"""
加载词表并构建Tokenizer对象
构造方法,封装了 __init_(),使用起来更方便
:parma vocab_file: 词表文件
:return: tokenizer对象
"""
def __init__(self, vocab_list: list[str]) -> None
"""
初始化tokenizer
:parma vocab_list: 词表列表
"""
def encode(self, sentence: Any) -> list[int]
"""
编码
相当于把分词方法 tokenize 和属性 word2index 合二为一
:parma sentence: 句子
:return: index列表
"""build_vocab 是一个类方法,因为创建 JiebaTokenizer 类时需要传入词表,创建词表的方法 build_vocab 需要先实例化 JiebaTokenizer 。如果把 build_vocab 设置为静态方法,那么它就无法使用 self 获取 unk_token 。设置为类方法后,build_token 也没法用 self 获取 unk_token,这时把 unk_token 设置为类属性。
实例方法 类方法 静态方法