Java 基础-基本语法
前言
学习尚硅谷的《Java零基础全套视频教程(宋红康主讲,java入门自学必备)》的第1到72分集。
第1阶段:Java基本语法,包括:Java概述、关键字、标识符、变量、运算符、流程控制(条件判断、选择结构、循环结构)、IDEA、数组。
- 第1阶段:Java基本语法
- Java概述、关键字、标识符、变量、运算符、流程控制(条件判断、选择结构、循环结构)、IDEA、数组
- 第2阶段:Java面向对象编程
- 类及类的内部成员
- 面向对象的三大特征
- 其它关键字的使用
- 第3阶段:Java语言的高级应用
- 异常处理、多线程、IO流、集合框架、反射、网络编程、新特性、其它常用的API等
神书:《Java核心技术》、《Effective Java》、《Java编程思想》。
1. 安装 Java 环境
下载 JDK
JDK 是什么?
- JDK (Java Development Kit)是 Java 程序开发工具包,包含 JRE 和开发人员使用的工具。
- JRE (Java Runtime Environment) 是 Java 程序的运行时环境,包含 JVM 和运行时所需要的核心类库。
在 Oracle 官网上下载 jdk1.8.0_271 和 jdk-17.0.12 。这两个版本都是 LTS 版本,我们主要使用 jdk 17,至于 jdk 8,主要用于阅读 jdk 8的部分源码。这部分源码在 jdk 17中是没有的。
接着将 jdk 压缩包解压后,移动到 /usr/lib/jvm 目录下。
tar -zxvf jdk-8u481-linux-x64.tar.gz jdk1.8.0_481/
sudo mv jdk1.8.0_481 /usr/lib/jvm
tar -zxvf jdk-17.0.12_linux-x64_bin.tar.gz jdk-17.0.12/
sudo mv jdk-17.0.12 /usr/lib/jvm查看 jdk 压缩包里面都有些什么东西:
❯ tree -L 1 jdk1.8.0_271
jdk1.8.0_271
├── bin # Java 工具,比如 javac
├── COPYRIGHT
├── include
├── javafx-src.zip
├── jmc.txt
├── jre # Java运行环境jre,已经包含在 jdk 中了
├── legal
├── lib
├── LICENSE
├── man
├── README.html
├── release
├── src.zip # Java 源码
├── THIRDPARTYLICENSEREADME-JAVAFX.txt
└── THIRDPARTYLICENSEREADME.txt
7 directories, 9 files不过 jdk 17 的源码
src.zip位于lib/目录下,而不是压缩包的根目录下。
切换 JDK 版本
在 ~/.zshrc 或 ~/.bashrc 中设置 JDK 的 PATH 环境变量,形如:
export JAVA_HOME="/your/jdk/path"
export PATH="$JAVA_HOME/bin:$PATH"配置 PATH 环境变量的目的是,在命令行使用 javac.exe 等工具时,任意目录下都可以找到这个工具所在的目录。
我用 AI 写了一个函数 switch_java() ,用来快速切换 JDK 版本,避免每次进入文件修改 PATH 的麻烦。
# ========== Java Version Switcher ==========
# 定义 JDK 路径
export JDK_8="/usr/lib/jvm/jdk1.8.0_271"
export JDK_17="/usr/lib/jvm/jdk-17.0.12"
export JDK_21="/usr/lib/jvm/java-21-openjdk-amd64"
# 切换 Java 版本的函数
switch_java() {
case "$1" in
8)
export JAVA_HOME="$JDK_8"
echo "Switched to JDK 8"
;;
17)
export JAVA_HOME="$JDK_17"
echo "Switched to JDK 17"
;;
21)
export JAVA_HOME="$JDK_21"
echo "Switched to OpenJDK 21"
;;
current)
echo "Current JAVA_HOME: $JAVA_HOME"
java -version
;;
list)
echo "Available JDKs:"
echo " 8 -> $JDK_8"
echo " 17 -> $JDK_17"
echo " 21 -> $JDK_21"
;;
*)
echo "Usage: switch_java <8|17|21|current|list>"
echo "Example: switch_java 17"
;;
esac
# 更新 PATH
export PATH="$JAVA_HOME/bin:$PATH"
# 验证
echo "Java version:"
java -version 2>&1 | head -1
}
# 设置默认版本(可选)
export JAVA_HOME="$JDK_17"
export PATH="$JAVA_HOME/bin:$PATH"将上面代码添加到 ~/.zshrc 文件末尾,并用 source ~/.zshrc 应用配置。接下来,让我们验证一下:
❯ switch_java 17
Switched to JDK 17
Java version:
java version "17.0.12" 2024-07-16 LTS
❯ java -version
java version "17.0.12" 2024-07-16 LTS
Java(TM) SE Runtime Environment (build 17.0.12+8-LTS-286)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.12+8-LTS-286, mixed mode, sharing)不过,终端重启后,jdk 会回到默认版本,所以 jdk 默认版本最好设置为平时常用的版本。
HelloWorld
开始创建我们的第一个 Java 程序 HelloWorld.java 。它的功能很简单,打印一个“Hello, world!”。
class HelloJava {
public static void main(String[] args) {
System.out.println("Hello, world!");
}
}使用 javac 将源文件 HelloWorld.java 编译成字节码文件 HelloJava.class ,字节码文件名恰好是我们定义的类名。
使用 java 运行字节码文件时,不带后缀名。
❯ javac HelloWorld.java
❯ ll
total 8.0K
-rw-rw-r-- 1 liyang liyang 426 Dec 17 21:53 HelloJava.class
-rw-rw-r-- 1 liyang liyang 111 Dec 17 21:52 HelloWorld.java
❯ java HelloJava.class
Error: Could not find or load main class HelloJava.class
Caused by: java.lang.ClassNotFoundException: HelloJava.class
❯ java HelloJava
Hello, world!我使用 lazyvim 代码模板创建类的时候,模板给我提供了 public class HelloJava {} 。这个 public 在我编译程序时报错。
原因在于,一个 Java 源文件只能有一个 public 的类,可以有多个非 public 的类。建议大家,不管是否是 public,都与源文件名保持一致,而且一个源文件尽量只写一个类,目的是为了好维护。
上面的 HelloWorld.java 虽然已经可以运行了,但它依然是不完整的,缺少必要的注释。注释是源文件中用于解释、说明程序的文字,注释在编译阶段会被过滤掉,不会放入 class 文件中。因而,反汇编 class 文件,自然也就看不到注释语句。
Java 中的注释类型,分为三种:单行注释、多行注释、文档注释。
// 这是单行注释
/*
这是多行注释
第二行
*/
/**
这是我的第一个Java程序
@author pluinyiasnhg
@version 1.0
*/
public class CommentTest {
/**
Java 程序的入口
@param args main方法的参数
*/
public static void main(String[] args) {
// 这是输出语句
System.out.println("Hello, world!");
}
}文档注释内容可以被 JDK 提供的工具 javadoc 所解析,生成一套以网页文件形式体现的该程序的说明文档。
javadoc -d mydoc -author -version CommentTest.java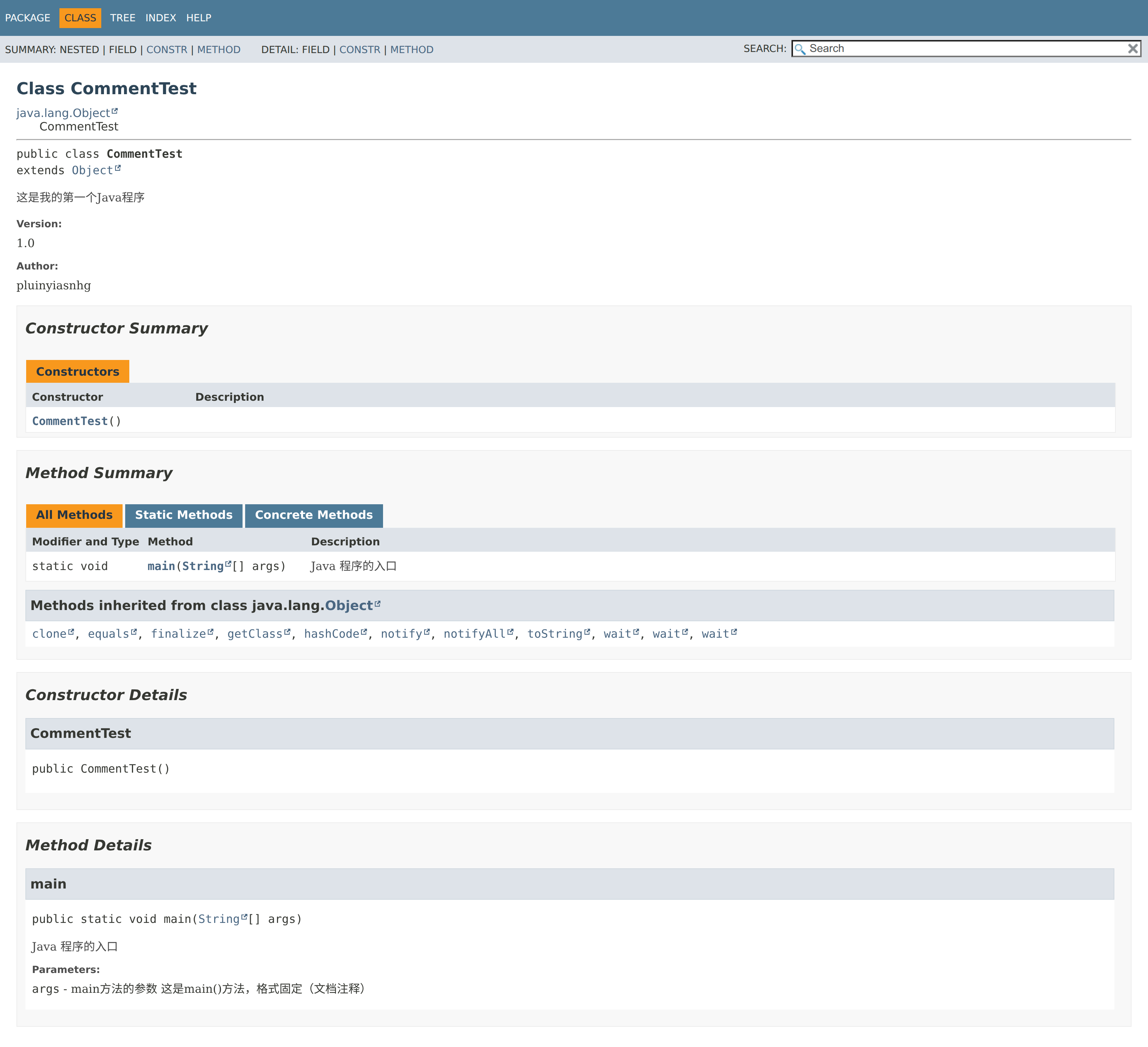
上面代码中的 System 是一个Java API ,Java 语言提供了大量的基础类,因此 Oracle 也为这些基础类提供了相应的说明文档,用于告诉开发者如何使用这些类,以及这些类里包含的方法。
Java API 文档,即 JDK 使用说明书、帮助文档,它就像是一本供人查阅的字典。
2. Java 变量
Java 中变量、方法、类等要素命名时使用的字符序列,称为标识符(identifier)。
标识符命名的规则(必须要遵守的,否则编译不通过):
- 由26个英文字母大小写,0-9 ,
_或$组成 - 数字不可以开头。
- 不可以使用关键字和保留字,但能包含关键字和保留字。
- Java中严格区分大小写,长度无限制。
- 标识符不能包含空格。
为什么标识符的声明规则里要求不能数字开头?
//如果允许数字开头,则如下的声明编译就可以通过:
int 123L = 12;
//进而,如下的声明中 l 的值到底是 123?还是变量 123L 对应的取值 12 呢? 出现歧义了。
long l = 123L;标识符的命名规范:
- 包名:多单词组成时所有字母都小写:
xxxyyyzzz。- 例如:java.lang、com.atguigu.bean
- 类名、接口名:多单词组成时,所有单词的首字母大写:
XxxYyyZzz- 例如:HelloWorld,String,System 等
- 变量名、方法名:多单词组成时,第一个单词首字母小写,第二个单词开始每个单词首字母大写:
xxxYyyZzz- 例如:age,name,bookName,main,binarySearch,getName
- 常量名:所有字母都大写。多单词时每个单词用下划线连接:
XXX_YYY_ZZZ- 例如:MAX_VALUE,PI,DEFAULT_CAPACITY
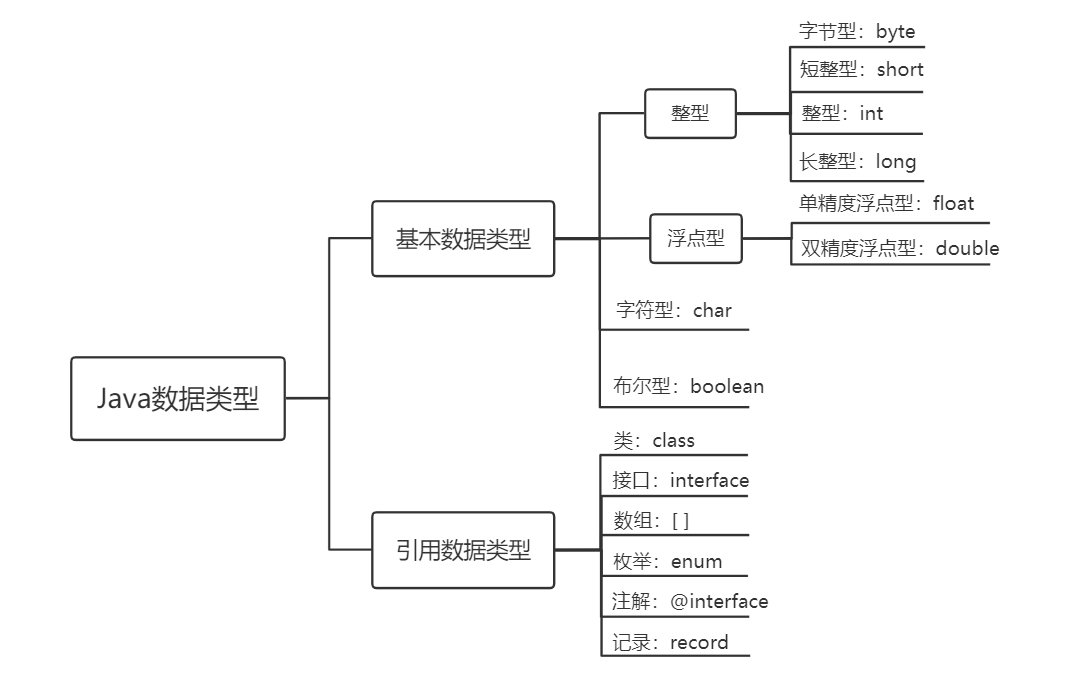
Java 中变量的数据类型分为两大类:
•基本数据类型:包括整数类型、浮点数类型、字符类型、布尔类型。
•引用数据类型:包括数组、 类、接口、枚举、注解、记录。
基本数据类型运算规则
在 Java 程序中,不同的基本数据类型(只有 7 种,不包含 boolean 类型)变量的值经常需要进行相互转换。
转换的方式有两种:自动类型提升和强制类型转换。
自动类型提升:将取值范围小(或容量小)的类型自动提升为取值范围大(或容量大)的类型 。
使用自动类型提升的情况:
- 当把存储范围小的值(常量值、变量的值、表达式计算的结果值)赋值给了存储范围大的变量时
- 当存储范围小的数据类型与存储范围大的数据类型变量一起混合运算时,会按照其中最大的类型运算。
- 当 byte,short,char 数据类型的变量进行算术运算时,按照 int 类型处理。
规则:当容量小的变量与容量大的变量做运算时,结果自动转换为容量大的数据类型。
byte 、short 、char ---> int ---> long ---> float ---> double
特别的:byte、short、char类型的变量之间做运算,结果为int类型。
说明:此时的容量小或大,并非指占用的内存空间的大小,而是指表示数据的范围的大小。
long(8字节) 、 float(4字节)强制类型转换:将取值范围大(或容量大)的类型强制转换成取值范围小(或容量小)的类型。
自动类型提升是 Java 自动执行的,而强制类型转换是自动类型提升的逆运算,需要我们自己手动执行。
使用强制类型转换的情况:
- 当把存储范围大的值(常量值、变量的值、表达式计算的结果值)强制转换为存储范围小的变量时,可能会损失精度或溢出。
- 当某个值想要提升数据类型时,也可以使用强制类型转换。这种情况的强制类型转换是没有风险的,通常省略。
- 声明 long 类型变量时,可以出现省略后缀的情况。float 则不同。
关于强制类型转换的第三条的说明:
long l1 = 123L;
long l2 = 123; // int 类型的 123 自动类型提升为 long 类型
//long l3 = 123123123123; //报错,因为 123123123123 超出了 int 的范围。
long l4 = 123123123123L;
//float f1 = 12.3; //报错,因为 12.3 看做是 double,不能自动转换为 float类型
float f2 = 12.3F;
float f3 = (float)12.3;运算符
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。
运算符的分类:
- 按照
功能分为:算术运算符、赋值运算符、比较(或关系)运算符、逻辑运算符、位运算符、条件运算符、Lambda运算符
| 分类 | 运算符 |
|---|---|
| 算术运算符(7个) | +、-、*、/、%、++、-- |
| 赋值运算符(12个) | =、+=、-=、*=、/=、%=、>>=、<<=、>>>=、&=、|=、^=等 |
| 比较(或关系)运算符(6个) | >、>=、<、<=、==、!= |
| 逻辑运算符(6个) | &、|、^、!、&&、|| |
| 位运算符(7个) | &、|、^、~、<<、>>、>>> |
| 条件运算符(1个) | (条件表达式)?结果1:结果2 |
| Lambda运算符(1个) | ->(第18章时讲解) |
- 按照
操作数个数分为:一元运算符(单目运算符)、二元运算符(双目运算符)、三元运算符 (三目运算符)
| 分类 | 运算符 |
|---|---|
| 一元运算符(单目运算符) | 正号(+)、负号(-)、++、--、!、~ |
| 二元运算符(双目运算符) | 除了一元和三元运算符剩下的都是二元运算符 |
| 三元运算符 (三目运算符) | (条件表达式)?结果1:结果2 |
赋值运算符
1. = +=、 -=、*=、 /=、%=
2. 说明:
① 当“=”两侧数据类型不一致时,可以使用自动类型转换或使用强制类型转换原则进行处理。
② 支持连续赋值。
③ +=、 -=、*=、 /=、%= 操作,不会改变变量本身的数据类型。下面代码中 s1 += 2 等同于 s1 = (short)(s1 + 2) 。
int m1 = 10;
m1 += 5; //类似于 m1 = m1 + 5 的操作,但不等同于。
System.out.println(m1); //15
short s1 = 10;
s1 += 2; //编译通过,因为在得到int类型的结果后,JVM自动完成一步强制类型转换,将int类型强转成short
System.out.println(s1); //12逻辑运算符
逻辑运算符,操作的都是boolean类型的变量或常量,而且运算得结果也是boolean类型的值。
运算符说明:
&和&&:表示"且"关系,当符号左右两边布尔值都是true时,结果才能为true。否则,为false。|和||:表示"或"关系,当符号两边布尔值有一边为true时,结果为true。当两边都为false时,结果为false!:表示"非"关系,当变量布尔值为true时,结果为false。当变量布尔值为false时,结果为true。^:表示“异或”关系,当符号左右两边布尔值不同时,结果为true。当两边布尔值相同时,结果为false。
区分“&”和“&&”:
- 相同点:如果符号左边是true,则二者都执行符号右边的操作
- 不同点:& 是"逻辑与",如果符号左边是false,则继续执行符号右边的操作
&& 是"短路与",如果符号左边是false,则不再继续执行符号右边的操作 - 建议:开发中,推荐使用 &&
区分“|”和“||” 与上面类似。
位运算符
1. << >> >>> & | ^ ~
2. 说明:
① << >> >>> & | ^ ~ :针对数值类型的变量或常量进行运算,运算的结果也是数值
②
<< : 在一定范围内,每向左移动一位,结果就在原有的基础上 * 2。(对于正数、负数都适用)
>> : 在一定范围内,每向右移动一位,结果就在原有的基础上 / 2。(对于正数、负数都适用)字符集
字符集:也叫编码表。是一个系统支持的所有字符的集合,包括各国家文字、标点符号、图形符号、数字等。
在存储的文件中的字符:
- ASCII 码,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。每个字符占用1字节。
- 拉丁码表,别名 Latin-1,用于显示欧洲使用的语言。ISO-8859-1 使用单字节编码,向下兼容 ASCII。
- GBK:最常用的中文码表。是在 GB2312 标准基础上的扩展规范,中文字符使用了双字节编码,共收录了 21003 个汉字,兼容 GB2312 标准,同时支持繁体汉字以及日韩汉字等。
- utf-8:可以用来存储世界范围内主要的语言的所有的字符。使用1-4个不等的字节表示一个字符。中文字符使用3个字节存储的。向下兼容ASCII。
在内存中的字符:
- Unicode,也称为统一码、标准万国码。一个字符(char)占用2个字节。
注意:在中文操作系统上,ANSI(美国国家标准学会)编码即为GBK;在英文操作系统上,ANSI编码即为ISO-8859-1。
3. 流程控制语句
switch-case 选择语句
语法格式:
switch (表达式) {
case 常量值 1:
语句块 1;
//break;
case 常量值 2:
语句块 2;
//break;
// ...
[default:
语句块 n+1;
break;
]
}使用注意点:
switch(表达式)中表达式的值必须是下述几种类型之一:byte,short,char,int,枚举(jdk 5.0),String (jdk 7.0);- case 子句中的值必须是常量,不能是变量名或不确定的表达式值或范围;
循环语句
for (1️⃣初始化部分; 2️⃣循环条件部分; 4️⃣迭代部分){
3️⃣循环体部分;
}
1️⃣初始化部分
while(2️⃣循环条件部分){
3️⃣循环体部分;
4️⃣迭代部分;
}
1️⃣初始化部分
do{
2️⃣循环体部分;
3️⃣迭代部分;
}while(4️⃣循环条件部分);do{}while();最后有一个分号- do-while 结构的循环体语句是至少会执行一次,这点和 for 、while 不一样
如何选择:
- 遍历有明显的循环次数(范围)的需求,选择 for 循环
- 遍历没有明显的循环次数(范围)的需求,选择 while 循环
- 如果循环体语句块至少执行一次,可以考虑使用 do-while 循环
- 本质上:三种循环之间完全可以互相转换,都能实现循环的功能
Scanner键盘输入
如何从键盘获取不同类型(基本数据类型、String 类型)的变量:使用 Scanner 类。
键盘输入代码的四个步骤:
- 导包:
import java.util.Scanner; - 创建 Scanner 类型的对象:
Scanner scan = new Scanner(System.in); - 调用 Scanner 类的相关方法(
next()/nextXxx()),来获取指定类型的变量 - 释放资源:
scan.close();
Scanner类中提供了获取byte \ short \ int \ long \float \double \boolean \ String类型变量的方法。
注意,没有提供获取 char 类型变量的方法。需要使用 next().charAt(0) 。
// 创建 Scanner 的对象
//Scanner 是一个引用数据类型,它的全名称是 java.util.Scanner
//scanner 就是一个引用数据类型的变量,赋给它的值是一个对象
//new Scanner(System.in)是一个 new 表达式,该表达式的结果是一个对象
//引用数据类型 变量 = 对象;
//这个等式的意思可以理解为用一个引用数据类型的变量代表一个对象,所以这个变量的名称又称为对象名
//我们也把 scanner 变量叫做 scanner 对象
Scanner scanner = new Scanner(System.in);//System.in 默认代表键盘输入4. IDEA 的安装与使用
IDEA,全称 IntelliJ IDEA,是 Java 语言的集成开发环境。
IDEA 的优势:
- 高度智能(快速的智能代码补全、实时代码分析、可靠的重构工具)
- 提示功能的快速、便捷、范围广
- 好用的快捷键和代码模板
- 精准搜索
系统设置
- 默认启动项目配置。『外观与行为->系统设置』不勾选“启动时重新打开项目”。
- 取消自动更新。『外观与行为->系统设置->更新』勾选“自动更新插件”,不勾选“检查插件更新”。
- 设置菜单和窗口字体和大小。『外观与行为->外观』中设置字体大小为13 。
- 设置编辑器字体和大小。在『编辑器->配色方案』的目录下设置。我设置为17 。
- 『编辑器->配色方案->语言默认设置』中可以修改注释等高亮颜色。
- 设置相对行号。『编辑器->常规->外观』中勾选“显示行号”,选择混合方案。
- 代码提示不区分大小写。『编辑器->常规->代码补全』不勾选“区分大小写”。
- 设置项目文件编码。在『编辑器->文件编码』中。
- 设置控制台的字符编码。在『编辑器->常规->控制台』中。
- 取消双击 shift 搜索。在『高级设置』勾选“禁用双击修改键快捷键”。
- 添加类头的文档注释信息。在『编辑器->文件和代码模板』的“Include”页面中,修改 File Header 模板。
/**
* ClassName: ${NAME}
* Package: ${PACKAGE_NAME}
* Description:
* @Author pluinyiasnhg
* @Create ${DATE} ${TIME}
* @Version 1.0
*/项目结构
层级关系:
project(工程) - module(模块) - package(包) - class(类)这些结构的划分,是为了方便管理功能代码。
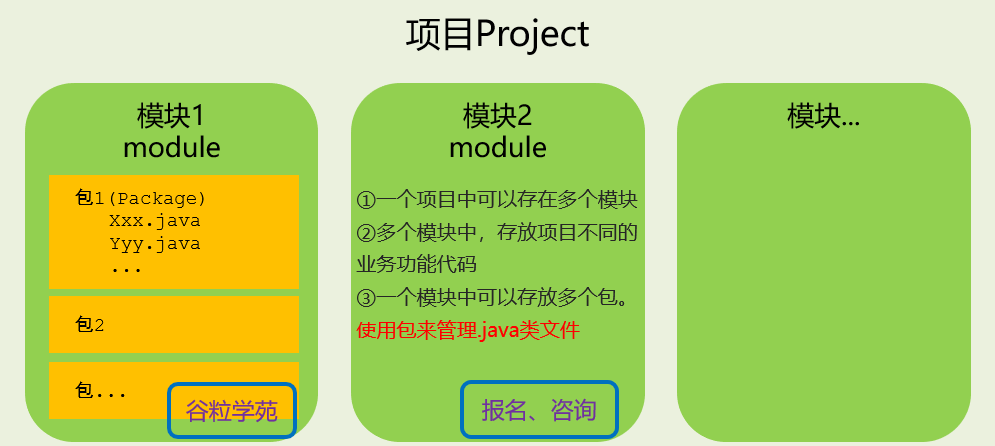
在 IntelliJ IDEA 中,Project 是最顶级的结构单元,然后就是 Module。目前,主流的大型项目结构基本都是多Module的结构,这类项目一般是按功能划分的,比如:user-core-module、user-facade-module 和 user-hessian-module等等,模块之间彼此可以相互依赖,有着不可分割的业务关系。因此,对于一个Project来说:
- 当为单Module项目的时候,这个单独的Module实际上就是一个Project。
- 当为多Module项目的时候,多个模块处于同一个Project之中,此时彼此之间具有
互相依赖的关联关系。 - 当然多个模块没有建立依赖关系的话,也可以作为单独一个“小项目”运行。
在一个 module 下,可以声明多个包(package),一般命名规范如下:
1.不要有中文
2.不要以数字开头
3.给包取名时一般都是公司域名倒着写,而且都是小写
比如:尚硅谷网址是www.atguigu.com
那么我们的package包名应该写成:com.atguigu.子名字。
快捷键
在 vim 快捷键基础上,学习一些 IDEA 的快捷键。
第1组:提高编写速度(上)
| 说明 | 快捷键 |
|---|---|
| 智能提示-edit | alt+enter |
| 提示代码模板-insert live template | ctrl+j |
| 使用xx块环绕-surround with ... | ctrl+alt+t |
| 调出生成getter/setter/构造器等结构-generate ... | alt+insert |
| 自动生成返回值变量-introduce variable ... | ctrl+alt+v |
| 向上移动一行-move line up | alt+shift+↑ |
| 向下移动一行-move line down | alt+shift+↓ |
| 方法的形参列表提醒-parameter info | ctrl+p |
第2组:提高编写速度(下)
| 说明 | 快捷键 |
|---|---|
| 批量修改指定的变量名、方法名、类名等-rename | shift+f6 |
| 抽取代码重构方法-extract method ... | ctrl+alt+m |
| 重写父类的方法-override methods ... | ctrl+o |
| 实现接口的方法-implements methods ... | ctrl+i |
| 选中的结构的大小写的切换-toggle case | ctrl+shift+u |
| 批量导包-optimize imports | ctrl+alt+o |
第3组:类结构、查找和查看源码
| 说明 | 快捷键 |
|---|---|
| 如何查看源码-go to class... | ctrl+n |
| 显示当前类结构,支持搜索指定的方法、属性等-file structure | ctrl+f12 |
| 退回到前一个编辑的页面-back | ctrl+alt+← |
| 进入到下一个编辑的页面-forward | ctrl+alt+→ |
| 打开的类文件之间切换-select previous/next tab | alt+←/→ |
| 光标选中指定的类,查看继承树结构-Type Hierarchy | ctrl+h |
| 查看方法文档-quick documentation | ctrl+q |
| 类的UML关系图-show uml popup | ctrl+alt+u |
| 定位某行-go to line/column | ctrl+g |
| 回溯变量或方法的来源-go to implementation(s) | ctrl+alt+b |
| 折叠方法实现-collapse all | ctrl+shift+ - |
| 展开方法实现-expand all | ctrl+shift+ + |
第4组:查找、替换与关闭
| 说明 | 快捷键 |
|---|---|
| 查找指定的结构 | ctlr+f |
| 快速查找:选中的Word快速定位到下一个-find next | ctrl+l |
| 查找与替换-replace | ctrl+r |
| 查询当前元素在当前文件中的引用,然后按 F3 可以选择 | ctrl+f7 |
| 全项目搜索文本-find in path ... | ctrl+shift+f |
第5组:调整格式
| 说明 | 快捷键 |
|---|---|
| 格式化代码-reformat code | ctrl+alt+l |
| 使用单行注释-comment with line comment | ctrl + / |
| 使用/取消多行注释-comment with block comment | ctrl + shift + / |
调试
运行编写好的程序时,可能出现的几种情况:
- 情况1:没有任何bug,程序执行正确!
- 情况2:运行以后,出现了错误或异常信息。但是通过日志文件或控制台,显示了异常信息的位置。
- 情况3:运行以后,得到了结果,但是结果不是我们想要的。
- 情况4:运行以后,得到了结果,结果大概率是我们想要的。但是多次运行的话,可能会出现不是我们想要的情况。比如:多线程情况下,处理线程安全问题。
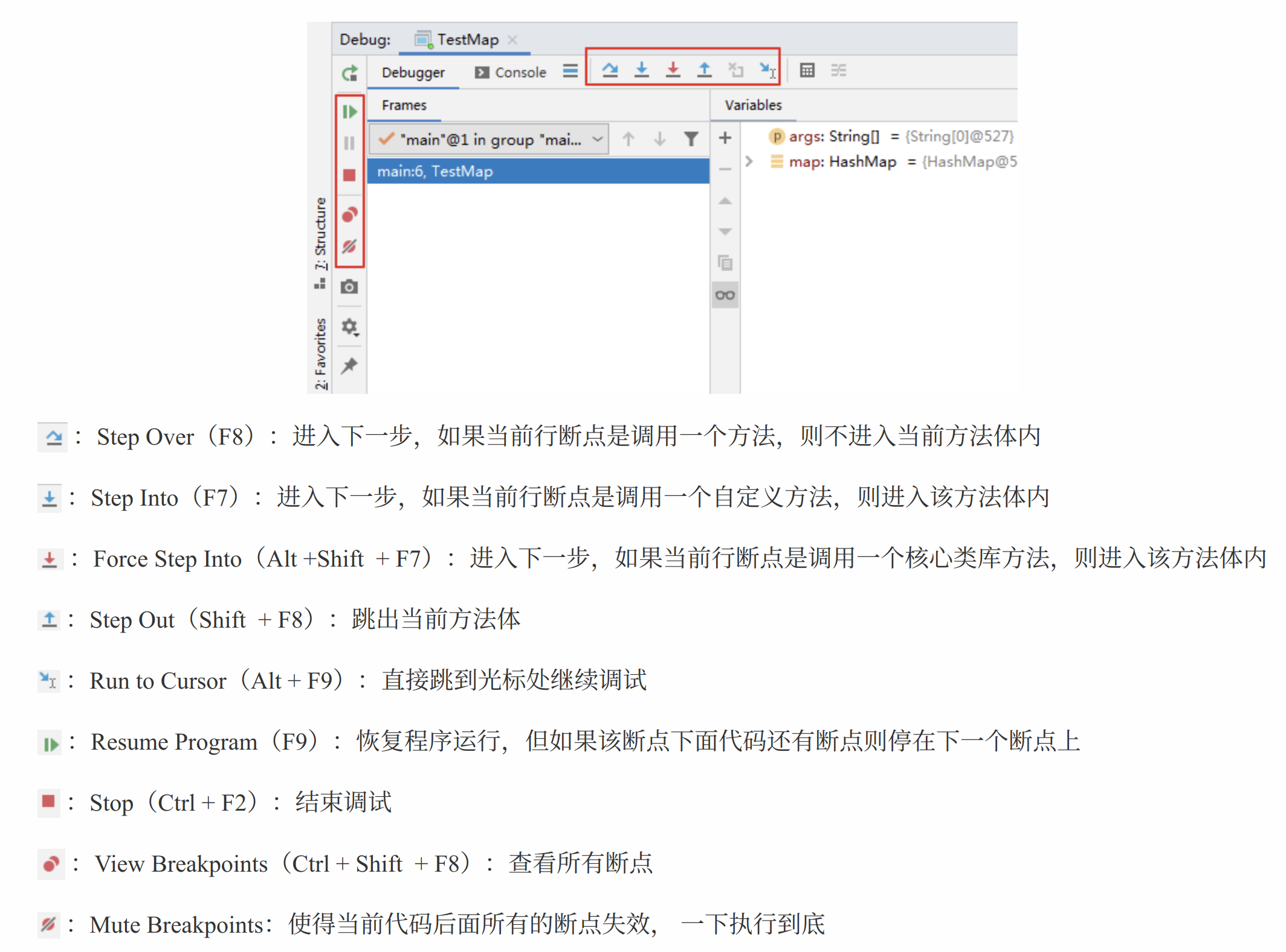
问题:使用Step Into时,会出现无法进入源码的情况。如何解决?
方案1:使用 force step into 即可
方案2:点击Setting -> Build,Execution,Deployment -> Debugger -> Stepping。把Do not step into the classess中的java.*、javax.*取消勾选即可。
插件
- Alibaba Java Coding Guidelines(Xeno)
阿里巴巴 Java 编码规范检查插件,检测代码是否存在问题,以及是否符合规范。
使用:在类中,右键,选择编码规约扫描,在下方显示扫描规约和提示。根据提示规范代码,提高代码质量。- jclasslib
可视化的字节码查看器。
使用:
在 IDEA 打开想研究的类。
编译该类或者直接编译整个项目( 如果想研究的类在 jar 包中,此步可略过)。
打开“view” 菜单,选择“Show Bytecode With jclasslib” 选项。
选择上述菜单项后 IDEA 中会弹出 jclasslib 工具窗口。- GenerateAllSetter
实际开发中还有一个非常常见的场景: 我们创建一个对象后,想依次调用 Setter 函数对属性赋值,如果属性较多很容易遗漏或者重复。
可以使用这 GenerateAllSetter 提供的功能,快速生成对象的所有 Setter 函数(可填充默认值),然后自己再跟进实际需求设置属性值。- Rainbow Brackets Lite - Free and Opensource(未安装)
给括号添加彩虹色,使开发者通过颜色区分括号嵌套层级,便于阅读。不喜欢花里胡哨,认为:所有括号两个颜色,比如一层括号颜色1,二层括号颜色2,三层括号颜色1……;光标所在的括号对,高亮为第三颜色。如此,就够用了。
- Statistic
代码统计工具。- Key Promoter X(未安装)
快捷键提示插件。当你执行鼠标操作时,如果该操作可被快捷键代替,会给出提示,帮助你自然形成使用快捷键的习惯,告别死记硬背。IDEA 快捷键,我不想记忆,熟悉如何运行代码就行。
- leetCode-editor (未安装)
在 IDEA 里刷力扣算法题。我用 LeetCode with labuladong 。
- One Dark Theme
没搞懂 One Dark Vivid Islands 和 One Dark Islands 区别在哪。
- IdeaVim
- CodeGeeX: Al Coding Assistant
5. 数组
一维数组的初始化
- 如果数组变量的初始化和数组元素的赋值操作同时进行,那就称为静态初始化。
- 静态初始化,本质是用静态数据(编译时已知)为数组初始化。此时数组的长度由静态数据的个数决定。
int[] arr = new int[]{1,2,3,4,5};
// 或
int[] arr;
arr = new int[]{1,2,3,4,5};
// 或
int[] arr = {1,2,3,4,5}; //类型推断
// int[] arr;
// arr = {1,2,3,4,5};- 数组变量的初始化和数组元素的赋值操作分开进行,即为动态初始化。
- 动态初始化中,只确定了元素的个数(即数组的长度),而元素值此时只是默认值,还并未真正赋自己期望的值。真正期望的数据需要后续单独一个一个赋值。
int[] arr = new int[5];
int[] arr1 = {1,2,3,4}; //类型推断
// 或
int[] arr;
arr = new int[5];
// int[] arr = new int[5]{1,2,3,4,5};//错误的,后面有{}指定元素列表,就不需要在[]中指定元素个数了。对于基本数据类型而言,默认初始化值各有不同。
对于引用数据类型而言,默认初始化值为 null(注意与 0 不同!)
| 数组元素类型 | 元素默认初始值 |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0L |
| float | 0.0F |
| double | 0.0 |
| char | 0或写为 '\u0000'(表现为空) |
| boolean | false |
| 引用类型 | null |
Java 虚拟机的内存划分
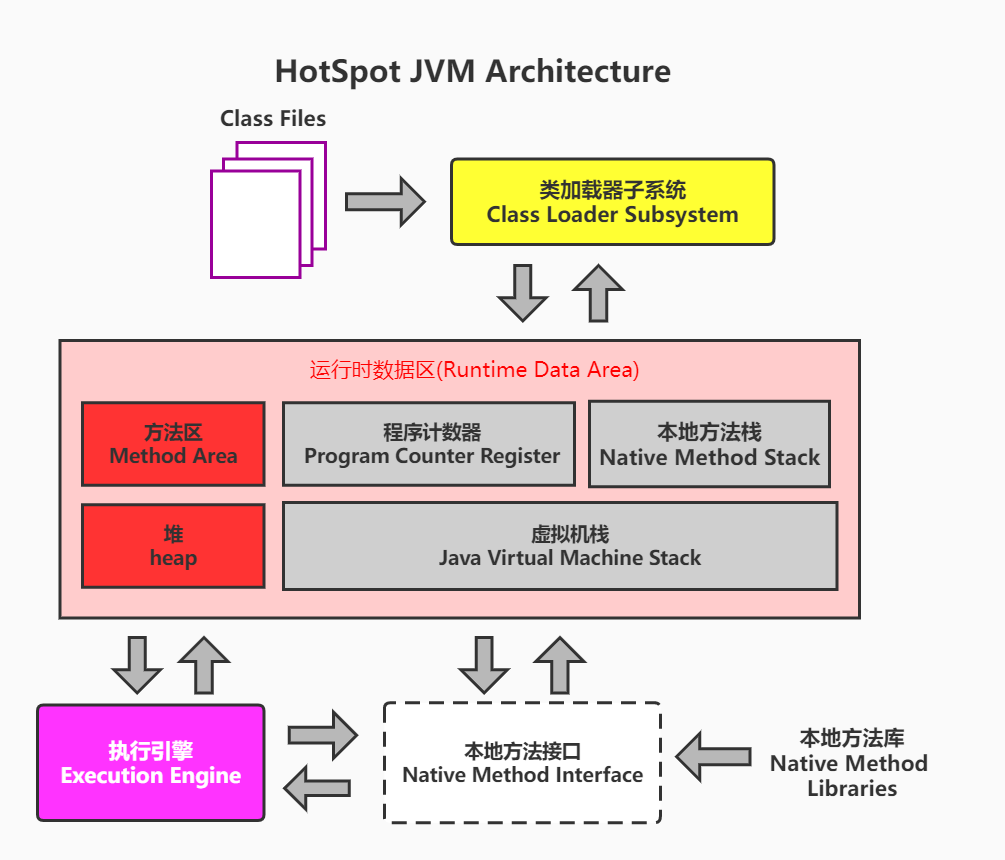
| 区域名称 | 作用 |
|---|---|
虚拟机栈 | 用于存储正在执行的每个Java方法的局部变量表等。局部变量表存放了编译期可知长度 的各种基本数据类型、对象引用,方法执行完,自动释放。 |
堆内存 | 存储对象(包括数组对象),new来创建的,都存储在堆内存。 |
方法区 | 存储已被虚拟机加载的类信息、常量、(静态变量)、即时编译器编译后的代码等数据。 |
| 本地方法栈 | 当程序中调用了native的本地方法时,本地方法执行期间的内存区域 |
| 程序计数器 | 程序计数器是CPU中的寄存器,它包含每一个线程下一条要执行的指令的地址 |
二维数组的初始化
静态初始化:数组变量的赋值和数组元素的赋值同时进行。
int[][] arr = {{1,2,3},{4,5,6},{7,8,9,10}};
int[][] arr = new int[][]{{1,2,3},{4,5,6},{7,8,9,10}};
int[][] arr;
arr = new int[][]{{1,2,3},{4,5,6},{7,8,9,10}};
//arr = new int[3][3]{{1,2,3},{4,5,6},{7,8,9,10}};//错误,静态初始化右边new 数据类型[][]中不能写数字注意特殊写法情况:
int[] x,y[];x是一维数组,y是二维数组。
动态初始化:数组变量的赋值和数组元素的赋值分开进行。
如果二维数组的每一个数据,甚至是每一行的列数,需要后期单独确定,那么就只能使用动态初始化方式了。动态初始化方式分为两种格式:
格式1:规则二维表:每一行的列数是相同的
int[][] arr = new int[3][2];格式2:不规则:每一行的列数不一样
//(1)先确定总行数
int[][] arr = new int[3][];
//此时只是确定了总行数,每一行里面现在是null
//(2)再确定每一行的列数,创建每一行的一维数组
arr[0] = new int[3];
arr[1] = new int[1];
arr[2] = new int[2];
//此时已经new完的行的元素就有默认值了,没有new的行还是null
//(3)再为元素赋值
二维数组名[行下标][列下标] = 值;数组的赋值
// 回顾赋值符号 = 。
int i = 10;
int j = i;
byte b = (byte)i; //强制类型转换
long l = i;//自动类型提升
//举例:数组
int[] arr1 = new int[10];
byte[] arr2 = new byte[20];
// arr1 = arr2; //编译不通过。原因:int[] 、 byte[] 是两种不同类型的引用变量
System.out.println(arr1); // [I@7344699f
System.out.println(arr2); // [B@6b95977
int[][] arr3 = new int[3][2];
// arr3 = arr1; //编译不通过。
arr3[0] = arr1;
System.out.println(arr3[0]); // [I@7344699f
System.out.println(arr1); // [I@7344699f
System.out.println(arr3); // [[I@7e9e5f8a