Python-其他
前言
学习尚硅谷的《python零基础教程》的第136到172分集。
结合了部分Python 官方的 Python3 tutorial 中文版 。
第9章 文件操作
Python 中操作文件的流程:
- 创建『文件对象』
- 操作文件(读取、写入 等)
- 关闭文件
[!info] 文件的分类
纯文本文件
- 读取和存储时,要遵循某种『字符编码』规范(如:UTF-8 等)进行编码和解码,最终以『二进制』的形式存储。
- 『纯文本文件』最终会呈现为:可以直接阅读的文本信息。
- 常见的『纯文本文件』有:
.txt.py.md.html等。二进制文件
- 读取和存储时,不涉及字符编码,会按照某种『文件格式规范』把内容转为『二进制』进行存储。
- 二进制文件需要由『能够识别其格式的软件』进行解析,最终的呈现形式多种多样(音频、视频、图像、幻灯片等)。
- 常见的二进制文件有:
.mp3.mp4.doc.ppt.jpg.png等。
创建文件对象
open() 返回一个文件对象 ,最常用的是 f = open(file, mode, encoding=None)。
file:要操作的文件路径mode:文件的打开模式r:读取(默认值)w:写入,并先截断文件x:排它性创建,如果文件已存在,则创建失败a:打开文件用于写入,如果文件存在,则在文件末尾追加内容b:二进制模式t:文本模式(默认值)+:打开用于更新(读取与写入)
encoding:纯文本文件的编码标准。对于二进制文件,该参数无用
读取文件
read方法
使用『文件对象』的read方法,读取文件中的内容。
read(size)中的size是可选参数。- 若不传递
size参数,表示:读取文件中所有的内容(注意内存占用)。 - 若传递了
size参数,表示:读取文件中指定个数的字符,或指定大小的字节。
- 若不传递
read会从上一次read的位置继续读取,若到达文件末尾后继续读取,将返回空字符串。
# 第一步:创建『文件对象』
file = open('a.txt', 'rt', encoding='utf-8')
# 读取二进制文件
# file = open('D:/test/girl.jpg', 'rb')
# 第二步:操作文件(读取)
# 多次调用read去逐步读取文件
r1 = file.read(2)
r2 = file.read(3)
r3 = file.read(4)
r4 = file.read()
print(r1, end='')
print(r2, end='')
print(r3, end='')
print(r4, end='')
# 用循环配合多次read(对内存友好)
while True:
result = file.read(10)
if result == '':
break
print(result, end='')
# 第三步:关闭文件
file.close()readline方法
使用文件对象的readline方法,读取文件中的一行。
readline(size)中的size是可选参数。- 若不传递
size参数,表示:读取当前这一行所有的内容。 - 若传递了
size参数,表示:表示读取当前行时,最多能读取的字符数,或字节数 - 注意:
size不是行数。
- 若不传递
readline方法,也是从上一次位置继续读取,若到达文件末尾后继续读取,返回空字符串。
f.readline() 和 f.read() 十分类似:都能读取到每行之间的换行符,但前者是按行读取,后者默认读取全部。不想读取到换行符且想一次性读取多行,可以用循环遍历整个文件对象。
file = open('a.txt', 'rt', encoding='utf-8')
# 使用 for 循环直接遍历文件对象(逐行遍历)
for line in file:
print(line, end='')
file.close()readlines方法
使用文件对象的readlines方法,一次性按“行”读完,返回一个列表。
readlines(hint)中的hint是可选参数。- 若不传递
hint参数,表示:读取当前文件的所有行。 - 若传递了
hint参数,表示:期望读取的【字符个数 或 字节数】(hint不是行数)。
- 若不传递
- 注意:由于
readlines是一次性读取文件的所有内容,所以不适合读取体积较大的文件。
上下文管理器
推荐使用with上下文管理器,结合for循环遍历,逐行读取文件。
with open('a.txt', 'rt', encoding='utf-8') as file:
for line in file:
print(line, end='')Python 中的with主要用于管理程序中“需要成对出现的操作”,例如:上锁 / 解锁、打开 / 关闭、借用 / 归还。
with 能得到一个上下文管理器的表达式 as 变量:
具体的事1
具体的事2
具体的事3[!info] 上下文管理器协议
__enter__方法:with中的代码执行【之前】调用,其返回值会赋值给as后的变量。__exit__方法:with中的代码执行【结束后】调用(无论是with中否出现异常都会调用)。
# 定义一个 Person 类,让其实例对象遵循:上下文管理器协议
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def speak(self):
print(f'我叫{self.name},年龄是{self.age}')
def __enter__(self):
print('-----我是进入的逻辑-----')
return self
# 当 with 中的代码发生异常时,__exit__ 方法的返回值规则如下:
# 🔸返回“真”:表示异常【已经】被处理,异常【不会】被继续抛出。
# 🔸返回“假”:表示异常【没有】被处理,异常【会】被继续抛出。
def __exit__(self, exc_type, exc_val, exc_tb):
print('-----我是离开的逻辑-----')
# exc_type : 异常类型
# exc_val : 异常对象
# exc_tb : 异常追踪信息
if exc_type:
print(f'异常类型:{exc_type}')
print(f'异常对象:{exc_val}')
print(f'异常追踪信息:{exc_tb}')
return True# 1.计算 with 后面的表达式,得到一个『上下文管理器』。
# 2.调用『上下文管理器』的 __enter__() 方法,并将其返回值赋给 as 后面的变量。
# 3.执行 with 所管理的代码。
# 4.无论代 with 中的代码,是正常结束,还是发生异常,都会自动调用『上下文管理器』的 __exit__ 方法。
with Person('张三', 18) as p1:
p1.speak()
p1.study()
print(666)
'''
-----我是进入的逻辑-----
我叫张三,年龄是18
-----我是离开的逻辑-----
异常类型:<class 'AttributeError'>
异常对象:'Person' object has no attribute 'study'
异常追踪信息:<traceback object at 0x7f1db497e9c0>
'''写入文件
rt+模式
r模式可以读取,+模式可以更新(读取或写入),所以rt+模式可读可写。
r模式打开文件后,文件指针在起始位置。- 由于
t是默认值,所以rt+中的t可以省略。
with open('a.txt', 'rt+', encoding='utf-8') as file:
# seek(offset, whence)方法:用于改变文件对象指针的位置,参数说明如下:
# offset:偏移量,要移动多少距离
# whence:参考点,从哪里开始计算偏移,有三种取值:
# 0:从文件开头计算(默认值)
# 1:从当前位置计算
# 2:从文件末尾计算
# 注意:在文本模式下,不要随意去定位中文字符位置,否则可能破坏文件编码。
file.seek(0, 0)
file.write('你好')wt+模式
w模式可以写入,+模式可以用于更新(读取或写入),所以wt+模式可读可写。
w模式打开文件后,文件指针在起始位置,但write方法执行完后,指针在文件结束位置。- 由于
t是默认值,所以wt+中的t可以省略。
with open('a.txt', 'wt+', encoding='utf-8') as file:
file.write('你好')
file.seek(0, 0)
result = file.read()
print(result)
xt+模式:x模式可以写入,+模式可以用于更新(读取或写入),所以xt+模式可读可写。at+模式:a模式可以追加内容,+模式可以用于更新(读取或写入),所以at+模式可读可写。
flush方法
Python 写入文件时,并不是每写一次就立刻落盘,而是:先写到“缓冲区”里。
flush方法:把缓冲区中的数据,立刻写入到文件中。
with open('demo.txt', 'at', encoding='utf-8') as file:
file.write('你好1')
file.write('你好2')
file.flush()
time.sleep(10000)
file.write('你好3')
file.write('你好4')目录操作
import os
import shutil
# os.mkdir(path):创建“单级”目录(如果目录已经存在,则会抛出异常)
os.mkdir('D:/demo')
# os.makedirs(path):创建“多级”目录(如果路径中的所有目录都已经存在,则会抛出异常)
os.makedirs('D:/demo/aa/bb')
# os.rmdir(path):删除空目录(如果目录不存在,或目录非空,都会抛出异常)
os.rmdir('D:/demo/aa/bb')
# os.removedirs(path):递归删除空目录,在成功删除末尾一级目录后,会“向上”尝试把父级目录也删除
# (直到父目录不是空目录)
os.removedirs('D:/demo/aa/bb')
# os.path.exists(path):判断路径是否存在(文件/目录都算)
result = os.path.exists('D:/demo/aa/bb')
print(result)
# os.path.isdir(path):用于判断路径,具体规则如下:
# 1.路径不存在 ================> 返回 False
# 2.路径存在,但指向的是文件 ====> 返回 False
# 3.路径存在,并且是目录 =======> 返回 True
result = os.path.isdir('D:/demo/aa/bb')
print(result)
# os.path.isfile(path):判断是否为文件
result = os.path.isfile('D:/demo/aa/bb')
print(result)
# os.scandir(path):扫描指定目录
result = os.scandir('D:/demo')
for item in result:
print('目录' if item.is_dir() else '文件', item.name)
# os.walk(path):按层级,递归地遍历指定目录下,所有的子目录和文件
result = os.walk('D:/demo')
for item in result:
print(item)
# ⚠️危险操作:删除有内容的目录
shutil.rmtree('D:/demo')第10章 进程与线程
同步(sync):
- 概念:发起一个任务之后,需要等该任务完成后,才能继续执行后续任务。
- 表现:当前执行流会被『阻塞』。
异步(async):
- 概念:发起一个任务之后,不必等该任务完成,就可以继续执行其他任务。
- 虽然不必等待任务完成,但任务完成后,仍然可以通过特定方式获取结果。
- 表现:当前执行流不会被『阻塞』。
进程:
- 一个正在运行的程序或软件,背后就对应着一个或多个进程。
- 进程是操作系统进行资源分配的基本单位。
- 每个进程都有自己独立的一块内存空间。
线程:
- 线程是进程内部的执行单元(一个进程中可以有多个线程)。
- 线程是操作系统进行 CPU 调度的基本单位。
- 同一进程内的线程共享进程资源。
[!info] Python 中查看进程 PID
os.getpid(): 获取当前进程 ID。os.getppid(): 获取父进程 ID。
创建进程
使用Process类
使用multiprocessing.Process类创建进程对象。
import os
import time
from multiprocessing import Process
print(100, __name__, os.getpid()) # 判断当前是主进程还是子进程
# 定义一个 speak 函数,功能是:每隔一秒说话一次(一共说话10次)
def speak():
for index in range(10):
print(f'我在说话{index}, 进程pid是:{os.getpid()}, 我的父进程是:{os.getppid()}')
time.sleep(1)
# 定义一个 study 函数,功能是:每隔一秒学习一次(一共学习15次)
def study():
for index in range(15):
print(f'我在学习{index}, 进程pid是:{os.getpid()}, 我的父进程是:{os.getppid()}')
time.sleep(1)
if __name__ == '__main__':
print('我是主进程中的【第一行】打印')
# 创建两个 Process 类的实例对象(进程对象),分别是 p1 和 p2。
# 注意点1:p1 和 p2 就对应着以后的两个子进程,在创建它们的时候,就要指定好他们要执行的任务。
# 注意点2:此时的 p1 和 p2 只是代码层面的两个进程对象,操作系统还没有创建p1和p2两个进程。
p1 = Process(target=speak)
p2 = Process(target=study)
# 调用进程对象的start方法,会立刻向操作系统申请一个进程,并且会将该进程交由操作系统进行调度。
p1.start()
p2.start()
print('我是主进程中的【最后一行】打印')[!warning] 注意:一定要写
if __name__ == '__main__'这个判断,原因如下:
- 当创建子进程时,Python 并不会把父进程内存里的 speak 函数直接交给子进程。
- Python会启动一个全新的 Python 解释器进程,重新执行当前的 .py 文件(作为模块)。不加判断会死循环。
- 在执行过程中,重新定义出一个 speak 函数,交给子进程。
在实例化 Process 时,可以传递以下参数:
group:默认值为None(应当始终为None)。target:子进程要执行的可调用对象,默认值为None。name:进程名称,默认为None,如果设置为None,Python 会自动分配名字。args:给target传的位置参数(元组)kwargs:给target传的关键字参数(字典)。daemon:标记进程是否为守护进程,取值为布尔值(默认为None,表示从创建方继承)。
def speak(a, b, msg):
for index in range(10):
print(f'{msg}--{a}--{b}--{current_process().name}--我在说话{index}, 进程pid是:{os.getpid()}, 我的父进程是:{os.getppid()}')
time.sleep(1)
def study():
for index in range(15):
print(f'我在学习{index}, 进程pid是:{os.getpid()}, 我的父进程是:{os.getppid()}')
time.sleep(1)
if __name__ == '__main__':
print('我是主进程中的【第一行】打印')
p1 = Process(target=speak, name='说话进程', args=(666, 888), kwargs={'msg':'尚硅谷'})
p2 = Process(target=study)
# print(p1.name)
# print(p2.name)
p1.start()
p2.start()
print('我是主进程中的【最后一行】打印')继承Process类
当子进程逻辑比较复杂,或者想把「进程 + 行为」封装成一个整体时,可以使用继承 Process 类的方式去创建进程,这种方式属于“面向对象风格”。
- 必须继承
Process类 - 把子进程要干的事,写进
run()方法里 - 依然使用
start方法启动进程,不要手动调用run()! - 若子进程不需要参数,可以不写
__init__,若需要参数,则需编写__init__ - 传给的子进程的参数,作为实例属性保存 。
from multiprocessing import Process
import os, time
class SpeakProcess(Process):
def __init__(self, a, b, **kwargs):
super().__init__(**kwargs)
self.a = a
self.b = b
def run(self):
for index in range(10):
print(f'{self.a}--{self.b}--我在说话{index}, 进程pid是:{os.getpid()}, 我的父进程是:{os.getppid()}')
time.sleep(1)
class StudyProcess(Process):
def run(self):
for index in range(15):
print(f'我在学习{index}, 进程pid是:{os.getpid()}, 我的父进程是:{os.getppid()}')
time.sleep(1)
if __name__ == '__main__':
print('我是主进程中的【第一行】打印')
p1 = SpeakProcess(100, 200)
p2 = StudyProcess()
p1.start()
p2.start()
p1.join()
p2.join()
print('我是主进程中的【最后一行】打印')进程池
截至目前,我们已经学会了创建多个进程一起工作,但是我们仍然面临一个问题:如果每来一个任务就创建一个进程,会很浪费系统资源,因为进程创建 / 销毁成本很高,当有大量任务时,系统资源浪费严重。
使用进程池的优势:如何使用进程池统一管理多个子进程,避免频繁创建 / 销毁进程带来的开销,因为进程池会提前创建固定数量的进程,反复使用它们来执行任务。
1️⃣创建『进程池执行器』、使用 submit 方法提交任务、使用 shutdown 方法等待任务完成。
def work(n):
print(f'work正在执行任务{n}.........{os.getpid()}')
time.sleep(1)
if __name__ == '__main__':
print('---------start-------------')
# 创建一个进程池执行器
executor = ProcessPoolExecutor(3)
# 使用 submit 方法提交任务(submit 只负责“提交任务”,不会阻塞主进程)
executor.submit(work, 1)
executor.submit(work, 2)
executor.submit(work, 3)
executor.submit(work, 4)
executor.submit(work, 5)
executor.submit(work, 6)
executor.submit(work, 7)
# shutdown 的作用:不再接收新的任务。
# wait=True 的作用:阻塞主进程,等待进程池中所有任务执行完毕。
executor.shutdown(wait=True)
print('---------end-------------')2️⃣获取子进程执行后的返回结果(Future类的实例对象 + result方法)
def work(n):
print(f'work正在执行任务{n}.........{os.getpid()}')
time.sleep(1)
return f'我是任务{n}的结果'
if __name__ == '__main__':
print('---------start-------------')
# 创建一个进程池执行器
executor = ProcessPoolExecutor(3)
# 使用 submit 方法提交任务(submit 只负责“提交任务”,不会阻塞主进程)
# f1 = executor.submit(work, 1)
# ......
# f7 = executor.submit(work, 7)
futures = [executor.submit(work, index) for index in range(1, 8)]
# 阻塞主进程,等待进程池中所有任务执行完毕。
executor.shutdown(wait=True)
# print(f1.result())
# ......
# print(f7.result())
for f in futures:
print(f.result())
print('---------end-------------')3️⃣使用 as_completed:按“完成顺序”获取结果
def work(n):
print(f'work正在执行任务{n}.........{os.getpid()}')
if n == 1:
time.sleep(15)
elif n == 2:
time.sleep(10)
else:
time.sleep(1)
return f'我是任务{n}的结果'
if __name__ == '__main__':
print('---------start-------------')
# 创建一个进程池执行器
executor = ProcessPoolExecutor(3)
# 使用 submit 方法提交任务(submit 只负责“提交任务”,不会阻塞主进程)
futures = [executor.submit(work, index) for index in range(1, 8)]
# 准备一个 result_list 去收集任务的具体结果
result_list = []
# 收集每个任务的结果
for f in as_completed(futures):
result_list.append(f.result())
# 阻塞主进程,等待进程池中所有任务执行完毕。
executor.shutdown(wait=True)
# 打印最终的结果
print(result_list)
print('---------end-------------')使用
add_done_callback方法,为任务添加完成时的回调函数。也可以实现上面同样的效果——按序获取结果。
if __name__ == '__main__':
print('---------start-------------')
# 创建一个进程池执行器
executor = ProcessPoolExecutor(3)
# 准备一个 result_list 列表去收集任务的结果
result_list = []
# 任务完成后的回调函数
def done_func(futrue):
result_list.append(futrue.result())
# 开启7个任务,并指定回调函数
for index in range(1, 8):
f = executor.submit(work, index)
f.add_done_callback(done_func)
# 等所有任务都完成
executor.shutdown(wait=True)
# 打印最终的结果(按“完成的顺序”获取)
print(result_list)
print('---------end-------------')4️⃣使用 map 方法批量提交任务。map方法会把这一批任务提交到进程池里执行,它会立刻返回一个生成器,真正的阻塞发生在:生成器取结果时,如 list(result)
if __name__ == '__main__':
print('---------start-------------')
# 创建一个进程池执行器
executor = ProcessPoolExecutor(3)
# 通过 map 方法批量提交任务(结果按照提交的顺序来)
results = executor.map(work, [1, 2, 3, 4, 5, 6, 7])
# 获取 results 生成器中的内容
print(list(results))
# 等所有任务都完成
executor.shutdown(wait=True)
print('---------end-------------')5️⃣️使用 with 实现进程池的“自动回收”,离开 with 代码块时自动执行 shutdown(wait=True) 。
if __name__ == '__main__':
print('---------start-------------')
# 创建一个进程池执行器
with ProcessPoolExecutor(3) as executor:
# 通过 map 方法批量提交任务(结果按照提交的顺序来)
results = executor.map(work, [1, 2, 3, 4, 5, 6, 7])
# 获取 results 生成器中的内容
print(list(results))
print('---------end-------------')进程控制
进程锁
为了防止多个进程同时打印或操作同一资源导致数据错乱,可以使用 Lock。
传统用法:
lock.acquire() # 上锁
# ... 临界区代码 ...
lock.release() # 释放锁上下文管理器用法 (推荐):
def study(lock):
for index in range(15):
# with lock: 会自动完成两件事:
# (1).进入前:自动执行 lock.acquire() 上锁
# (2).离开后:自动执行 lock.release() 释放锁
# 好处:即便代码块里发生异常,也能保证释放锁,避免“卡死”
with lock:
print('A', end='')
print('B', end='')
print('C', end='')
print('D')
time.sleep(1)传统 Lock 在面对多次上锁时,会产生死锁状态,解决办法是使用 RLock。
import os
import time
from multiprocessing import Process, Lock, RLock
def speak(lock):
for index in range(10):
lock.acquire()
lock.acquire()
print('好好', end='')
print('学习', end='')
print('天天', end='')
print('向上')
lock.release()
lock.release()
time.sleep(1)
def study(lock):
for index in range(15):
with lock:
print('A', end='')
print('B', end='')
print('C', end='')
print('D')
time.sleep(1)
if __name__ == '__main__':
print('我是主进程中的【第一行】打印')
lock = RLock()
p1 = Process(target=speak, args=(lock,))
p2 = Process(target=study, args=(lock,))
p1.start()
p2.start()
print('我是主进程中的【最后一行】打印')join方法
- 作用:阻塞当前进程(通常是主进程),直到调用
join的那个进程执行完毕。 - 参数:
join(timeout),timeout为超时时间(秒)。如果时间到了进程还没结束,主进程就不等了,会继续执行。
import os
import time
from multiprocessing import Process
def speak():
pass
def study():
pass
if __name__ == '__main__':
print('我是主进程中的【第一行】打印')
p1 = Process(target=speak)
p2 = Process(target=study)
p1.start()
# 让主进程等 p1 5秒钟
p1.join(5)
p2.start()
# p1.join() # 让主进程等 p1 进程执行完毕后,主进程再继续执行。
# p2.join() # 让主进程等 p2 进程执行完毕后,主进程再继续执行。
print('我是主进程中的【最后一行】打印')注意点:
p.join()不是让进程 p 等,而是让“执行这行 join 代码的那个进程”(这里是主进程)去等,等的是 p 这个进程。- 当达到了 timeout 所指定的时间后,进程并不会终止,只是“不再等”了。
- join 必须在 start 之后
terminate方法
- 作用:向操作系统申请强制终止进程。
- 注意:使用
terminate终止进程,不会执行 finally 代码块。 - 辅助方法:
is_alive()可用于查看进程是否还“活着”。
import os
import time
from multiprocessing import Process
def speak():
try:
for index in range(10):
print(f'我在说话{index}, 进程pid是:{os.getpid()}, 我的父进程是:{os.getppid()}')
time.sleep(1)
# 注意:使用 terminate 终止进程,不会引起 finally 执行!
finally:
print('我是finally里的逻辑')
if __name__ == '__main__':
print('我是主进程中的【第一行】打印')
p1 = Process(target=speak)
p1.start()
time.sleep(3)
print('我是主进程,我准备强制终止p1进程........')
# 向操作系统申请强制终止p1进程
p1.terminate()
# 等操作系统彻底终止掉了p1进程
p1.join()
# 看一下p1进程是否“活着”
print(p1.is_alive())
print('我是主进程中的【最后一行】打印')守护进程
守护进程是一种 “依附于主进程存在的子进程”,一旦主进程结束,它就会被自动终止。简言之:主进程一死,守护进程必跟着死。
- 守护进程必须是子进程。
- 主进程结束,守护进程也会随之结束。
- 守护进程中,不允许再创建新的子进程。
- 必须在 start 之前。
start()之后,不能再设置daemon。
守护进程常用于:
- 后台监控类任务
- 日志 / 统计 / 采样 类任务
- 辅助型“陪跑任务”
import os
import time
from multiprocessing import Process
def monitor():
while True:
try:
with open('log.txt', 'r', encoding='utf-8') as file:
lines = sum(1 for _ in file)
except FileNotFoundError:
lines = 0
print(f'我是【守护进程({os.getpid()})】,log.txt 共有{lines}行')
time.sleep(1)
if __name__ == '__main__':
print(f'我是主进程({os.getpid()})中的【第一行】代码')
p1 = Process(target=monitor, daemon=True)
p1.start()
# 向文件中写入数据
with open('log.txt', 'a', encoding='utf-8') as file:
for index in range(5):
file.write(f'尚硅谷{index}\n')
file.flush()
time.sleep(1)
print(f'我是主进程({os.getpid()})中的【最后一行】代码')
'''
我是主进程(130573)中的【第一行】代码
我是【守护进程(130574)】,log.txt 共有1行
我是【守护进程(130574)】,log.txt 共有2行
我是【守护进程(130574)】,log.txt 共有3行
我是【守护进程(130574)】,log.txt 共有4行
我是【守护进程(130574)】,log.txt 共有5行
我是主进程(130573)中的【最后一行】代码
'''进程通信
进程之间不共享内存,因此也就不共享任何变量。但有些对象是天然被多个进程共享的,比如 Lock 和 RLock,以及下面的 multiprocessing.Queue 。
Queue实现通信
队列(Queue)是:一种“先进先出”的数据结构(先放进去的数据,一定会先取出来)。
| 队列操作 | 解释 | 返回值 |
|---|---|---|
Queue() | 创建一个队列(不限制大小) | |
Queue(3) | 创建一个队列(最多能保存3个元素) | |
q.put(obj) | 往队列里放数据(入队) | |
q.get() | 从队列里取数据(出队) | 取出的数据 |
q.empty() | 判断队列是否为空 | True / False |
q.full() | 判断队列是否已满 | True / False |
q.qsize() | 获取队列长度 | 队列长度 |
这里的 Queue 来自多进程
multiprocessing。
q = Queue(3)
q.put(10)
q.put(20)
q.put(30)
# (1).当队列已满,继续 put,就会进入等待模式,等别人调用get方法,取走一个元素
q.put(400) # 无限等待
# (2).当队列已满,执行:put(元素, timeout=秒数),就会等待指定秒数,然后报错
q.put(400, timeout=3)
# (3).put_nowait 方法,会直接向队列中添加元素,不会进入等待模式,若队列已满,会抛出异常。
# 备注:put_nowait 等价于 put(元素, block=False),block的默认值为 True
q2.put_nowait(400)
q2.put(400, block=False)
# get读多了,也会进入等待模式
q2.get()
q2.get()
q2.get()
# (1).当队列已空,继续 get,就会进入等待模式。
q2.get()
# (2).当队列已空,执行 get(timeout=秒数),就会等待指定秒数。
q2.get(timeout=3)
# (3).get_nowait 方法,会直接读取队列中的元素,不会进入等待模式,若队列已空,会抛出异常
# 备注:get_nowait 等价于 get(block=False)
q2.get_nowait()
q2.get(block=False)使用 Queue 实现进程通信:一个进程负责生产数据,另一个进程负责消费数据,中间通过 Queue 进行“传话”。队列先进先出的特性,保证数据不会乱掉。
import time
from multiprocessing import Process, Queue
# 子进程1:往队列里放数据
def test1(q):
for index in range(5):
print(f'【test1】放入数据:{index}')
q.put(index)
time.sleep(0.5)
# 子进程2:从队列里取数据
def test2(q):
for index in range(5):
data = q.get()
print(f'【test2】取出数据:{data}')
time.sleep(1)
if __name__ == '__main__':
# q 是在主进程中创建的,但可以被子进程使用,因为 multiprocessing.Queue 是跨进程的。
q = Queue()
p1 = Process(target=test1, args=(q,))
p2 = Process(target=test2, args=(q,))
p1.start()
p2.start()
p1.join()
p2.join()Pipe实现通信
Pipe 就像一根“水管”,一头负责发送,另一头负责接收。
import time
from multiprocessing import Process, Pipe
def test1(con1):
# recv 方法:从管道中接收数据。
data = con1.recv()
print(f'test1接收了{data}')
def test2(con2):
time.sleep(2)
# send 方法:向管道中发送数据。
con2.send(100)
print('test2发送了100')
if __name__ == '__main__':
# duplex 被置为 True (默认值),那么该管道是双向的
# duplex 被置为 False ,那么该管道是单向的,
# 即 con1 只能用于接收消息,而 con2 仅能用于发送消息。
con1, con2 = Pipe(duplex=False)
p1 = Process(target=test1, args=(con1,))
p2 = Process(target=test2, args=(con2,))
p1.start()
p2.start()
p1.join()
p2.join()创建线程
线程是进程中的执行单位:任何一个正在运行的 Python 程序,至少都有一个线程!
- 一个进程里,至少有一个线程(主线程)
- 一个进程里,也可以有多个线程
- 多个线程之间会: 共享进程的内存空间、 但执行顺序由操作系统调度。
# print('主进程中的代码') 确实属于主进程,但更准确地说,是运行在主进程里的主线程中。
if __name__ == '__main__':
print('主进程中的代码')使用Thread类
在实例化 Thread 时,可以传递以下参数:
group:默认值为None(应当始终为None)。target:子线程要执行的可调用对象,默认值为None。name:线程名称,默认为None,如果设置为None,Python 会自动分配名字。args:给target传的位置参数(元组)kwargs:给target传的关键字参数(字典)。daemon:标记线程是否为守护线程,取值为布尔值(默认为None,表示从创建方继承)。
import os
import time
from threading import get_native_id, Thread, RLock
def speak(lock):
for index in range(5):
with lock:
print(f'我在说话{index}, 进程pid是:{os.getpid()}, 线程编号:{get_native_id()}')
time.sleep(1)
def study(lock):
for index in range(5):
with lock:
print(f'我在学习{index}, 进程pid是:{os.getpid()}, 线程编号:{get_native_id()}')
time.sleep(1)
if __name__ == '__main__':
print(f'-------start------- 进程pid是:{os.getpid()}, 线程编号:{get_native_id()}')
lock = RLock()
# 使用 Thread 创建线程对象
t1 = Thread(target=speak, args=(lock,))
t2 = Thread(target=study, args=(lock,))
# 调用线程对象的 start 方法,会立刻将该线程交由操作系统进行调度。
t1.start()
t2.start()
# 让主线程等 t1和t2 线程执行完毕后,主线程再继续执行。
t1.join()
t2.join()
print('-------end-------')继承Thread类
和继承Process创建进程一样,我们也可以继承Thread创建线程。
import os
import time
from threading import get_native_id, Thread, RLock
class SpeakThread(Thread):
def __init__(self, lock, **kwargs):
super().__init__(**kwargs)
self.lock = lock
def run(self):
for index in range(5):
with self.lock:
print(f'我在说话{index}, 进程pid是:{os.getpid()}, 线程编号:{get_native_id()}')
time.sleep(1)
class StudyThread(Thread):
def __init__(self, lock, **kwargs):
super().__init__(**kwargs)
self.lock = lock
def run(self):
for index in range(5):
with self.lock:
print(f'我在学习{index}, 进程pid是:{os.getpid()}, 线程编号:{get_native_id()}')
time.sleep(1)
if __name__ == '__main__':
print(f'-------start------- 进程pid是:{os.getpid()}, 线程编号:{get_native_id()}')
lock = RLock()
# 继承 Thread 类创建线程对象
t1 = SpeakThread(lock)
t2 = StudyThread(lock)
# 调用线程对象的 start 方法,会立刻将该线程交由操作系统进行调度。
t1.start()
t2.start()
# 让主线程等 t1和t2 线程执行完毕后,主线程再继续执行。
t1.join()
t2.join()
print('-------end-------')线程池
线程池的具体语法,以及各个方法的作用,都和进程池一样。
- 创建『线程池执行器』、使用
submit方法提交任务、使用 shutdown 方法等待任务完成。 - 获取子线程执行后的返回结果(
Future类的实例对象 +result方法) - 使用
as_completed:按“完成顺序”获取结果 - 使用
add_done_callback方法,为任务添加完成时的回调函数 - 使用 map 方法批量提交任务(注意:map方法本身不阻塞,但读取其返回的生成器对象是阻塞的,并且得到结果的顺序,与任务分配的顺序是一致的)
- 使用 with 实现线程池的自动回收,离开 with 代码块时自动执行
shutdown(wait=True)。
import time
from concurrent.futures import ThreadPoolExecutor
from threading import get_native_id, RLock
def work(n, lock):
with lock:
print(f'work正在执行任务{n}.........{get_native_id()}')
if n == 1:
time.sleep(15)
elif n == 2:
time.sleep(10)
else:
time.sleep(1)
return f'任务{n}的结果'
if __name__ == '__main__':
print('---------start-------------')
with ThreadPoolExecutor(3) as executor:
# 创建线程锁
lock = RLock()
# 使用map方法批量提交任务
result = executor.map(work, [1, 2, 3, 4, 5, 6, 7], [lock]*7)
# 打印最终的结果
print(list(result))
print('---------end-------------')GIL 全局解释器锁
GIL锁是 CPython 解释器中的一把互斥锁。
- 无论 CPU 有多少个核心,在某一时刻,只允许同一个进程中的一个线程去执行 Python 代码。
- CPython 解释器中的多线程模型,本质上是并发,而不是并行!(是快速切换,而不是同时进行)
- 如果没有 GIL 锁,那么 Python 底层就可能会出现引用计数错误,导致内存爆炸。

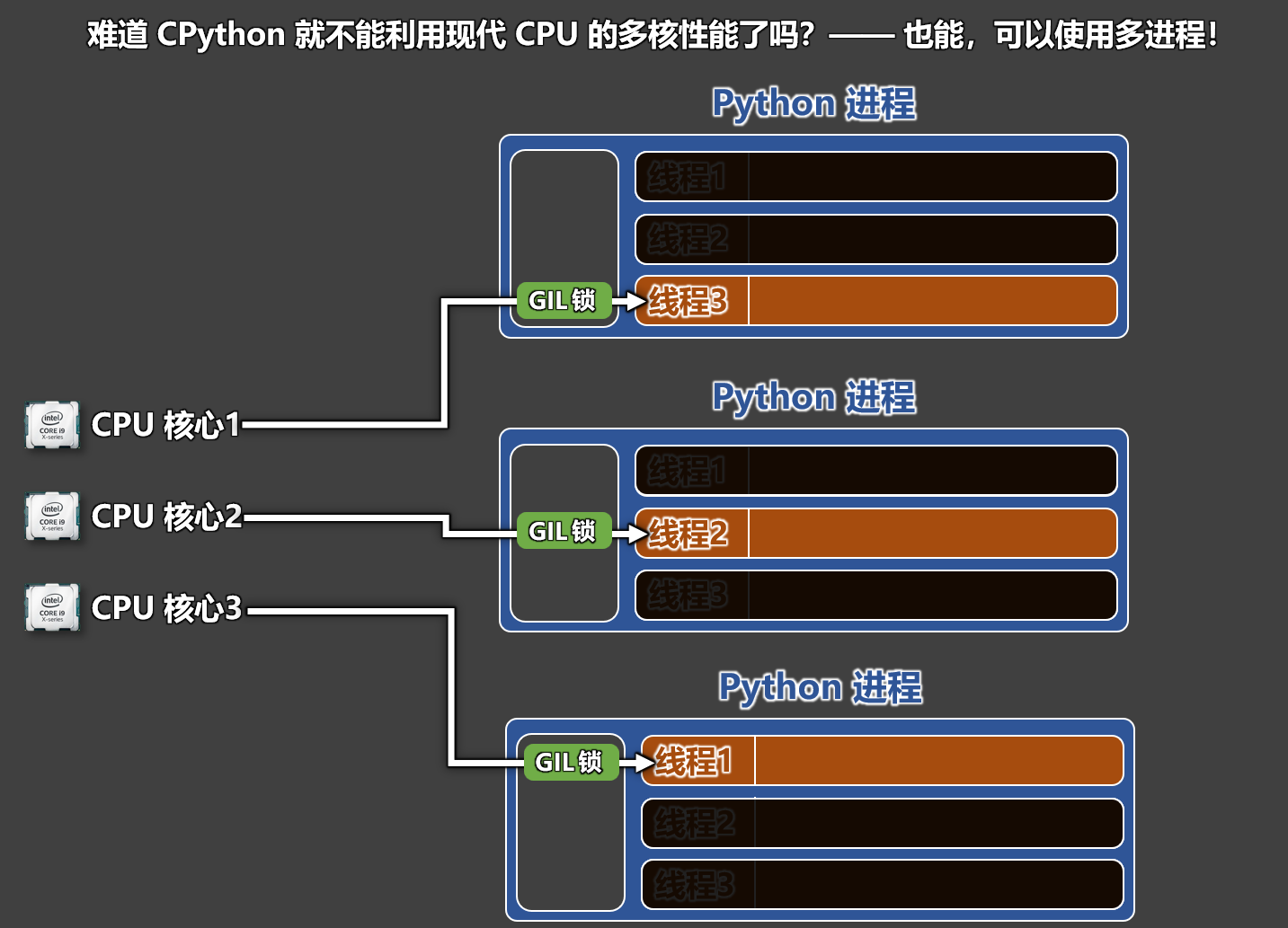
GIL锁和之前代码中使用的 Lock/RLock 不是一个东西。
- GIL 为了确保 Cpython 解释器级别的数据安全,作为日常编码来说,我们对 GIL 是无感的
- 但对于
Lock/Rlock是实际编码中使用较多的,Lock/Rlock是为了确保业务逻辑的完整
| 对比维度 | GIL (Global Interpreter Lock) 全局解释器锁 | Lock / RLock |
|---|---|---|
| 核心本质 | 解释器级别的强制限制 | 代码级别的逻辑约定 |
| 谁来控制 | Python 解释器:解释器自动加锁、遇到 IO 或超时自动释放。 | 程序员:需要写代码 lock.acquire() 和 lock.release()。 |
| 保护对象 | 保护**“解释器不崩”**,维护引用计数、垃圾回收等底层结构的线程安全。 | 保护**“数据不算错”**,维护用户定义的变量、操作顺序等业务逻辑的完整性。 |
| 作用范围 | 全局唯一:一个进程里只有一个 GIL,管着所有线程。 | 按需创建:可以创建 100 把不同的锁,分别保护 100 个不同的业务逻辑。 |
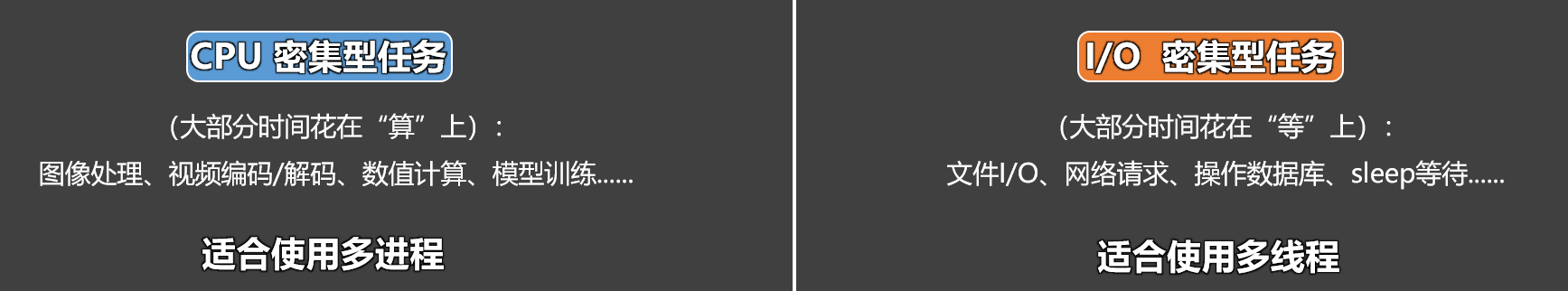
第11章 协程
协程(Coroutine),是一种线程内部的任务调度机制,它通过事件循环,在用户态中实现任务的挂起与恢复执行,从而在遇到 IO 操作时,不让 CPU 等待,而是继续执行其它需要 CPU 的任务。
协程的本质:在一个线程里,趁着某些任务在等 IO,把 CPU 交给其它任务去用。所有任务,由事件循环统一调度,事件循环负责:调度任务、判断是否该挂起、决定何时恢复执行。
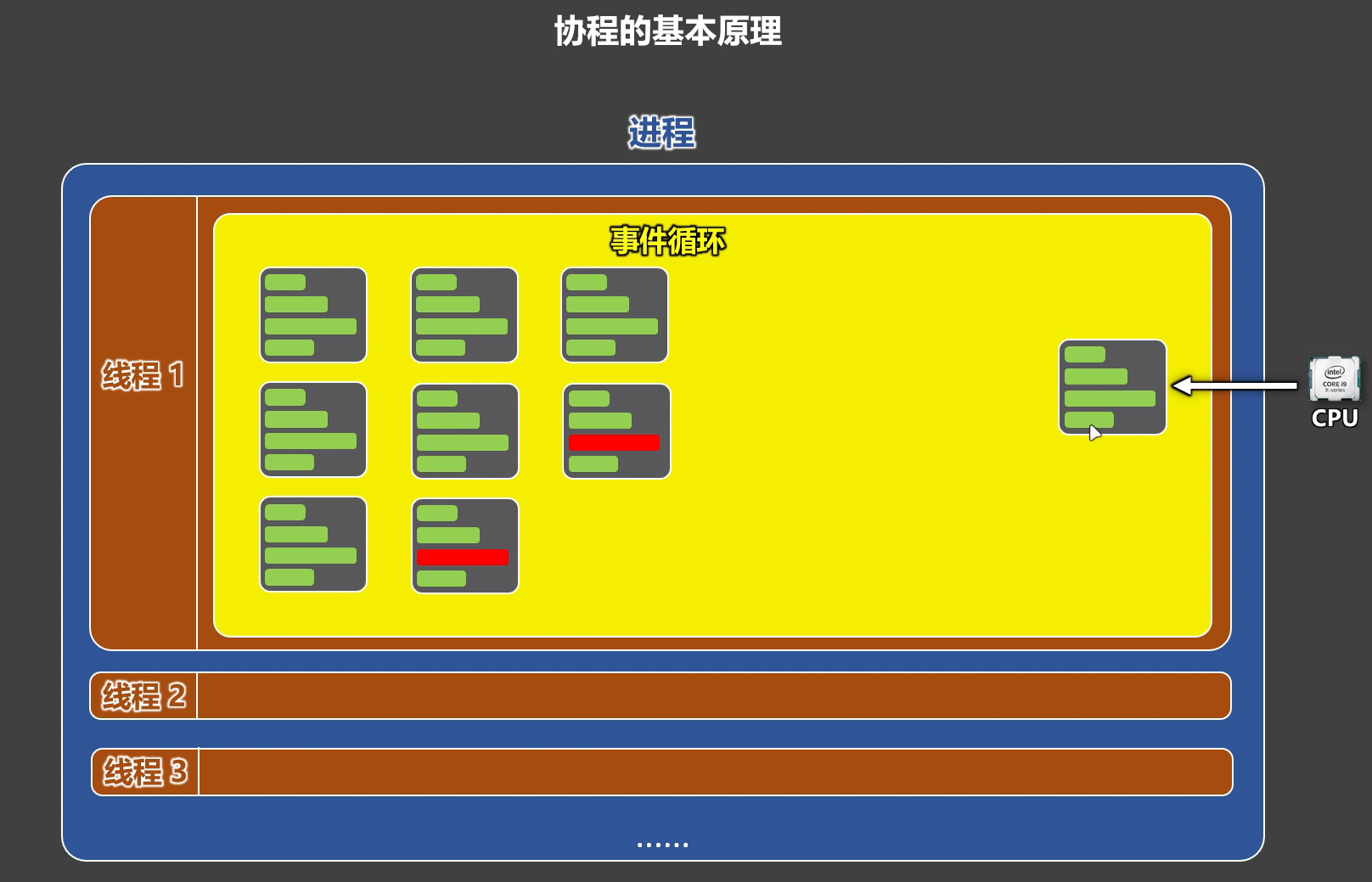
- 协程不是线程,也不是进程:协程是程序员在用户态,用代码“设计出来”的任务切换机制。操作系统不知道协程的存在,并且 CPU 看不见协程。
- 协程发生在一个线程内部:协程不是线程之间的切换,而是线程内部多个任务之间的切换。
- 协程的目标是尽量减少线程切换:在单线程场景下,最大化 CPU 利用率,特别适合 IO 密集型任务。
协程对象
协程对象(coroutine Object):调用『协程函数』,就会得到『协程对象』。
协程函数(coroutine Function):使用
async关键字修饰的函数,就是协程函数。
# 定义一个协程函数
async def work():
print('work开始')
print('work执行中......')
print('work结束')
return '工作结果'
# 调用协程函数,会得到协程对象
# 注意:调用『协程函数』,并不会执行『协程函数』中的代码。
coroutine_object = work()将协程对象交给asyncio.run(),asyncio.run()会将协程对象包装成一个任务交给事件循环。
# asyncio.run 方法做了3件事:
# 1.创建一个事件循环。
# 2.将收到的协程对象,包装成一个任务(task),交给事件循环。
# 3.启动事件循环。
# 注意:asyncio.run 会阻塞当前线程,直到任务执行完毕,并返回该任务 return 的最终结果。
result = asyncio.run(coroutine_object)
print(result)
'''
work开始
work执行中......
work结束
工作结果
'''await 关键字
await 关键字有三个作用:
- 挂起:await 会暂停当前协程的执行。
- 等待:遇到 await,事件循环会立即安排 await 后面的对象去执行,并等待该对象执行完成,并且可以拿到执行结果。
- 执行 await 后面的对象时,遇到了【await I/O操作】,事件循环会进行任务调度;否则,事件循环不干预
- 恢复:当 await 后的对象执行完毕,事件循环会恢复之前被挂起的协程,该协程会从当时挂起的位置继续执行,并拿到返回值。
- 注意:await 后面只能写『可等待对象』,常见可等待对象有:协程对象、Future对象、Task对象。
自动管理资源
# 创建 MCP 客户端会话对象
# 1. 执行到 await 时,当前协程被挂起
# 2. ClientSession() 开始异步执行(如网络请求)
self.session = await self.exit_stack.enter_async_context(
ClientSession(self.stdio, self.write)
)
# 直接使用 self.session,无需担心关闭exit_stack.enter_async_context() 的主要作用就是自动管理异步资源的生命周期,确保资源的正确打开和关闭。
- 自动关闭:当
exit_stack退出时(比如程序结束、发生异常、主动清理),它会自动调用ClientSession的__aexit__方法来关闭会话 - 异常安全:即使中间代码抛出异常,会话也会被正确关闭,不会造成资源泄漏
- 简化代码:避免了手动写
try...finally或async with的繁琐
# 手动管理生命周期
self.session = ClientSession(self.stdio, self.write)
await self.session.__aenter__() # 手动进入上下文
try:
# 使用会话...
pass
finally:
await self.session.__aexit__(None, None, None) # 手动退出上下文多个任务同步执行
使用 await 实现多个任务同步执行。下面代码中每次IO等待,事件循环不会干预任务调度。
import asyncio
import time
# 定义一个协程函数
async def work(n, delay):
print(f'work{n}开始')
print(f'work{n}执行中......')
# 模拟一个IO等待
await asyncio.sleep(delay)
print(f'work{n}结束')
return f'work{n}的返回值'
async def main():
print('main开始')
start = time.time()
# 调用三次work函数,分别得到三个协程对象
coroutine1 = work(1, 2)
coroutine2 = work(2, 2)
coroutine3 = work(3, 2)
# 此处会等待coroutine1执行完成
res1 = await coroutine1
print(res1)
# 等待上面的coroutine1完成后,再等待coroutine2完成
res2 = await coroutine2
print(res2)
# 等待上面的coroutine2完成后,再等待coroutine3完成
res3 = await coroutine3
print(res3)
print('main结束', time.time() - start) # main结束 6.007376670837402
return '我是main的返回值'
# 将协程对象交给事件循环
result = asyncio.run(main())
print(result)
'''
...
work1开始
work1执行中......
work1结束
work1的返回值
work2开始
work2执行中......
work2结束
work2的返回值
work3开始
work3执行中......
work3结束
work3的返回值
...
'''多个任务异步执行
使用asyncio.create_task()方法向事件循环中添加任务,从而实现多个任务异步执行。
import asyncio
import time
# 定义一个协程函数
async def work(n, delay):
print(f'work{n}开始')
print(f'work{n}执行中......')
# 模拟一个IO等待
await asyncio.sleep(delay)
print(f'work{n}结束')
return f'work{n}的返回值'
async def main():
print('main开始')
start = time.time()
# asyncio.create_task 会把一个协程对象包装成一个可被事件循环调度的任务,并注册到事件循环中
task1 = asyncio.create_task(work(1, 2))
task2 = asyncio.create_task(work(2, 2))
task3 = asyncio.create_task(work(3, 2))
# 此处会等待task1执行完成
res1 = await task1
print(res1)
# 等待上面的task1完成后,再等待task2完成
res2 = await task2
print(res2)
# 等待上面的task2完成后,再等待task3完成
res3 = await task3
print(res3)
print('main结束', time.time() - start) # main结束 2.002239227294922
return '我是main的返回值'
# 将协程对象交给事件循环
result = asyncio.run(main())
print(result)
'''
...
work1开始
work1执行中......
work2开始
work2执行中......
work3开始
work3执行中......
work1结束
work2结束
work3结束
...
'''上面代码中,每个任务一遇到IO操作,事件循环就会将该任务挂起,将CPU切换给下一个任务。所以,很快三个任务,都在等待2秒的IO操作完成。
asyncio.gather方法可以把多个协程对象丢给事件循环,并在全部执行完后,一次性拿到所有结果。
async def main():
print('main开始')
start = time.time()
# 把多个协程对象同时丢给事件循环,并在全部执行完后,一次性拿到所有结果。
result = await asyncio.gather(work(1, 2), work(2, 2), work(3, 2))
print(result)
print('main结束', time.time() - start) # 也是2秒左右
return '我是main的返回值'
# 将协程对象交给事件循环
result = asyncio.run(main())
print(result)下载图片案例
使用传统方式下载图片:图片是一张一张下载的,当前图片没有下载完成,后一张图片的下载就不能开始,这属于典型的同步下载。
import requests
def download_picture(url):
print(f'开始下载:{url}')
# 发送网络请求,获取这张图片
response = requests.get(url)
print('下载完毕')
# 保存图片到本地
with open(url[-10:], 'wb') as file:
file.write(response.content)
def main():
url_list = [
'https://n.sinaimg.cn/spider20260129/217/w600h417/20260129/3e26-917ee55a8a42b8626807c332c24981de.png',
'https://n.sinaimg.cn/finance/transform/97/w630h267/20260129/97c4-b211cc51784830f09ee19e450475c93b.png',
'https://n.sinaimg.cn/spider20260129/539/w1439h700/20260129/e09a-cc2ca319e00f701ccfca3ebc62aa8772.png'
]
for url in url_list:
download_picture(url)
main()使用协程方式下载图:多张图片会几乎同时发起下载请求,当某一张图片在等待网络数据返回时,其它图片的下载任务并不会被阻塞,而是可以继续执行,这属于典型的协程并发下载。
import aiohttp
import asyncio
async def download_picture(session, url):
print(f'开始下载:{url}')
# 发送网络请求,获取这张图片,请求发出去后,要等待服务器把数据返回,等的这段时间就是IO等待
response = await session.get(url)
# 等待数据(图片数据可能分多次传输,需要等待数据全部读完,等的这段时间也是IO等待)
content = await response.read()
print('下载完毕')
# 保存图片到本地
with open(url[-10:], 'wb') as file:
file.write(content)
# 释放连接资源(告诉 aiohttp,这个连接我不用了,你可以回收了)
await response.release()
async def main():
url_list = [
'https://n.sinaimg.cn/spider20260129/217/w600h417/20260129/3e26-917ee55a8a42b8626807c332c24981de.png',
'https://n.sinaimg.cn/finance/transform/97/w630h267/20260129/97c4-b211cc51784830f09ee19e450475c93b.png',
'https://n.sinaimg.cn/spider20260129/539/w1439h700/20260129/e09a-cc2ca319e00f701ccfca3ebc62aa8772.png'
]
# 创建会话对象(发请求的工具)
session = aiohttp.ClientSession()
# 创建多个协程对象
coroutine_list = [download_picture(session, url) for url in url_list]
# 将多个协程对象交给事件循环
await asyncio.gather(*coroutine_list)
# 关闭会话
await session.close()
asyncio.run(main())