Python-基本语法
前言
学习尚硅谷的《python零基础教程》的第1到88分集。
结合了部分Python 官方的 Python3 tutorial 中文版 。
Learning Python, 6th Edition 官网
调试
# 使用 pdb 调式
python3 -m pdb file.py
# 使用 -i,当脚本退出时(无论成功结束还是遇到错误),Python都会自动打开交互模式(>>>)
# 这时候也可以导入 pdb 模块
python3 –i script.py第0章 使用 Python 解释器
python 解释器的安装路径通常在 /usr/share/bin 路径下面,在 shell 中输入 python 就能启动解释器,想要退出解释器,可以输入 quit() 或者快捷键 Ctrl-d(Linux)、Ctrl-z(Windows)。
如果使用 miniconda 管理 python 虚拟环境,默认的 base 环境在 [安装路径]/miniconda3 下面,其他虚拟环境在 [安装路径]/miniconda3/env/[环境名] 。
启动解释器时候,可以传递参数,比如 -i 在运行脚本文件的同时进入交互模式,-c 后接命令,-m 后接模块名。更多的参数详见命令行和环境。
解释器读取命令行参数,把脚本名与其他参数转化为字符串列表存到 sys 模块的 argv 变量里。
- 未给定输入参数时,
sys.argv[0]是空字符串 - 给定脚本名是
'-'(标准输入)时,sys.argv[0]是'-' - 使用
-c时,sys.argv[0]是'-c' - 使用
-m时,sys.argv[0]就是包含目录的模块全名 - 解释器不处理
-c或-m之后的选项,而是直接留在sys.argv中由命令或模块来处理
默认情况下,python 源代码文件是以 UTF-8 格式编码。如果想要指定其他编码格式,则要声明文件的编码,在源代码文件的第一行添加特殊注释,格式如下。其中,encoding 可以是 Python 支持的任意一种 codecs。
# -*- coding: encoding -*-第一行的规则也有一种例外情况,源码以 UNIX "shebang" 行 开头。此时,编码声明要写在文件的第二行。
#!/usr/bin/env python3
# -*- coding: cp1252 -*-第1章 Python 核心基础
变量
变量是数据的“代号”,它可以和数据建立绑定关系,通过变量可以使用数据,或更新数据。之所以叫变量,是因为:它和某个值的绑定关系,可以随时改变。
在 Python 中,变量的创建与赋值是同时完成的。也就是说,当程序中出现一个变量时,它必须立即与某个值(比如 None )建立绑定关系。
标识符
什么是标识符?在程序中我们给: 变量、函数、类.....所起的名字,统称为标识符,即:在程序中所有我们可以自己起的名字,都是标识符
常见的三种命名风格:
- 大驼峰(UpperCamelCase): 每个单词的首字母大写,例如:
UserName - 小驼峰(lowerCamelCase): 首词的首字母小写,后面单词首字母大写,例如:
userName - 蛇形(snake_case):单词间用下划线连接,例如:
user_name
Python 标识符推荐使用『蛇形(snake_case)』写法。
Python 类名使用大驼峰写法。
常量
常量,是在程序中一旦被赋值,就不希望被修改的量(区别于变量)。
Python 中没有强制的常量机制。当强制对常量进行修改时,最终也能改掉,但要自觉不改,这是 Python 程序员之间的约定。
注释
注释是对代码的备注和解释,在代码执行的时,通常不起任何作用。
单行注释
在 Python 中#后的一行内内容,会被视为注释。
# name 是张三的名字
name = '张三'
# age 是张三的年龄
age = 18
# weight 是张三的体重(单位:kg)
weight = 65.2
print(name, age, weight) # 这是一句打印[!info] 关于注释的书写格式
Python官方建议:在#和注释的内容之间加一个空格,在代码和#之间加两个空格。
多行注释
多行注释又称“块注释” ,Python 中的多行注释使用的是一组三引号(单引号,双引号都可以)。
1️⃣多行注释可以换行,但不能嵌套。
"""
我是一些注释
我还是一些注释
"""2️⃣多行注释本质是一个多行字符串。
📢注意:Python 中并没有真正的多行注释语法,所谓多行注释的本质其实还是字符串。
print(
"""
Hello World
Hello world
"""
)文件编码注释
文件编码又称“字符编码”,文件编码注释写在 Python 文件的首行,是一种特殊的注释。
它的作用是:指定当前文件的字符编码。
# coding=utf-8
print('你好啊!')数据类型
查看数据类型
通过type()可以查看数据类型,type()会返回当前数据的具体类型。
# 使用变量接收 type() 返回的类型
result1 = type('张三')
result2 = type(18)
result3 = type(72.5)
print(result1) # <class 'str'>
print(result2) # <class 'int'>
print(result3) # <class 'float'>[!warning] 在 Python 中:变量无类型,数据有类型。
例如a = 10,其中a是没有类型的,但a所关联的数据10是有类型的,10是整型,我们经常说a是整型,其实是一种不太严谨的表述,严谨的表述应该是:a所对应的数据10是整型。
也可以把变量交给type(),最终返回的是:变量所对应的数据的类型。
name = '张三'
age = 18
weight = 72.5
# 打印这三个数据类型
print(type(name)) # <class 'str'>
print(type(age)) # <class 'int'>
print(type(weight)) # <class 'float'>整型
所谓整型就是没有小数点的数字, Python 中的整型,可以是任意大小的整数,包括负整数。
Python 中存储整数上限值的大小取决于:计算机的内存和处理能力。
a = 9 ** 9999 # 9的9999次方
print(a) # 打印x运行上面代码会报错,报错提及了"Exceeds the limit (4300 digits)",但这并不代表 Python 最大只能表示4300位的数,比如我们把print删掉,会发现代码正常运行,并且此时的a也是可以正常参与数学运算的。
问题出在 print 上:调用print(a)时,Python 底层会把a的类型转换成『字符串类型』再输出,而从 Python3.11 起,Python 对超大整数转换字符串的长度进行了限制,默认位数是4300位。
# 通过如下代码,可以解除字符串转换时的`4300`位限制
import sys
sys.set_int_max_str_digits(0) # 设置为0表示不作任何限制
x = 9 ** 9999 # 9的9999次方
print(x) # 打印x浮点型
所谓浮点型,就是带小数点的数字,比如:3.14、-0.5、2.0都是浮点数。
浮点型有两种表示方法:带小数点的数字、科学计数法表示。
字符串
字符串的四种定义方式:
# 单引号和双引号的写法是等价的,二者都不能直接换行(要用圆括号才能换行),单引号用的多。
message1 = '尚硅谷,让天下没有难学的技术!'
message2 = "尚硅谷,让天下没有难学的技术!"
# 三个单引号的写法,可以直接换行,并且可以作为多行注释使用。
message3 = '''尚硅谷,让天下没有难学的技术!'''
# 三个双引号的写法,可以直接换行,也可以作为多行注释使用,还能作为文档字符串使用。
message4 = """尚硅谷,让天下没有难学的技术!"""字符串的三种格式化输出方式:
# 写法1:直接用加号进行拼接,写起来很麻烦,而且只能是字符串之间拼接
name = '张三'
gender = '男'
weight = 65.2
age = 12
info1 = '我叫' + name + ',我是' + gender + '生'
# 写法2:使用占位符。
name = '张三'
gender = '男'
weight = 65.2
age = 12
info2 = '我叫%s,我是%s生,我体重是%f,年龄是%d' % (name, gender, weight, age)
# 写法3:使用 f-string,这是目前 Python 最推荐的方式。
name = '张三'
gender = '男'
weight = 65.2
age = 12
info3 = f'我叫{name},我是{gender}生,我体重是{weight},年龄是{age}'[!info] 写法2中占位符的具体规则
%s占位字符串%f占位浮点数%i占位整数%d占位十进制的整数%s是万能的(如果我们提供的数据不是字符串,那 Python 就会把数据转成字符串)
转义字符
在字符串中,有些字符不能直接写(换行、制表符、引号等)这时就要使用转义字符。
| 转义字符 | 表示的含义 |
|---|---|
\' | ' |
\" | " |
\n | 换行 |
\\ | \ |
\b | 删除前一个字符 |
\r | 使光标回到本行开头,覆盖输出 |
\t | 表示水平制表符(让光标跳转到下一个制表位) |
# 使用 \\ 输出 \
print('D:\\nice')
# 使用 \b 删除前一个字符
print('helloo\b')
# 使用 \r 使光标回到本行开头,覆盖输出。可以用作进度条
print('67%\r68%')
# 使用 \t 表示水平制表符(让光标跳转到下一个制表位)
# 一个制表位到底是几位,是不确定的,但我们可以通过在字符串后面加.expandtabs()来指定位数。
print('1234123412341234')
print('ab\tcd')
print('abc\td')
print('abcd\ta')
print('我是\t中文')
# 运行结果如下:
1234123412341234
ab cd
abc d
abcd a
我是 中文原始字符串。如果不希望前置 \ 的字符转义成特殊字符,可以使用原始字符串,在引号前添加 r 即可:
>>> print('C:\some\name') # 这里 \n 表示换行符!
C:\some
ame
>>> print(r'C:\some\name') # 请注意引号前的 r
C:\some\name数据类型转换
int(x) :将x转换为一个整数。
int(15.6)
int('79')
int(' 79 ')
int(48)
# int('15.6')
# ValueError: invalid literal for int() with base 10: '15.6'float(x) :将x转换为一个浮点数。
float(18)
float('15.6')
float(' 5.7 ')
float(14.8)
float('48')str(x) :将对象x转换为一个字符串。
任何类型都可以转成字符串类型。
运算符
算术运算符:
| 运算符 | 说明 | 示例 | 结果 |
|---|---|---|---|
| + | 加 | 9 + 7 | 16 |
| - | 减 | 7 - 2 | 5 |
| * | 乘 | 3 * 4 | 12 |
| / | 除 | 9 / 6 | 1.5 |
| // | 取整除(取整) | 9 // 6 | 1 |
| % | 取余(取模) | 9 % 6 | 3 |
| ** | 指数 | 2 ** 3 | 8 |
赋值运算符:
| 运算符 | 含义 | 示例 | 等价代码 |
|---|---|---|---|
| = | 赋值运算 | age = 18 | |
| += | 加法赋值运算 | age += 1 | age = age + 1 |
| -= | 减法赋值运算 | age -= 1 | age = age - 1 |
| *= | 乘法赋值运算 | price *= 0.8 | price = price * 0.8 |
| /= | 除法赋值运算 | pay /= 5 | pay = pay / 5 |
| //= | 取整赋值运算 | apple //= 14 | apple = apple // 14 |
| %= | 取模赋值运算 | seconds %= 60 | seconds = seconds % 60 |
| **= | 指数赋值运算 | a **= b | a = a ** b |
比较运算符:
| 运算符 | 作用 | 比较结果 | 示例代码 |
|---|---|---|---|
| == | 判断左右两侧是否相等 | 成立为 True,否则 False | a = 5, b = 5 → a == b 为 True |
| != | 判断左右两侧是否不等 | 成立为 True,否则 False | a = 5, b = 3 → a != b 为 True |
| > | 判断左侧是否大于右侧 | 成立为 True,否则 False | a = 5, b = 4 → a > b 为 True |
| < | 判断左侧是否小于右侧 | 成立为 True,否则 False | a = 4, b = 5 → a < b 为 True |
| >= | 判断左侧是否大于等于右侧 | 成立为 True,否则 False | a = 5, b = 5 → a >= b 为 True |
| <= | 判断左侧是否小于等于右侧 | 成立为 True,否则 False | a = 6, b = 6 → a <= b 为 True |
布尔类型是int类型的子类型,底层的本质是用1表示True,用0表示False。
Python中除
0以外的任何数,转为布尔值后都为 True
Python中除空字符串以外的任何字符串,转为布尔值都是 True。比如bool('0')返回 True
逻辑运算符:not and or
and 和 or 都具有“逻辑短路”能力。
print(False and 3 / 0) # False
print(3 > 9 and 3 / 0) # False
print(True or 3 / 0) # True
print(9 > 3 or 3 / 0) # Trueand 返回的不一定是布尔值,它返回的是某个参与计算的值本身。
and会先看左边,如果左边是“假”,就直接返回左边,否则返回右边。- 若参与
and运算的值不是布尔值,那 Python 会自动转为布尔值,然后再进行逻辑操作。
print(2 - 2 and True) # 0
print('' and True)
print(True and 8 / 2) # 4.0
print(3 + 3 and 3 * 4) # 12or返回的也不一定是布尔值,它返回的是参与计算的值本身
or会先看左边,如果左边为“真”,就直接返回左边,否则返回右边- 若参与
or运算的值不是布尔值,那 Python 会自动转为布尔值,然后再进行逻辑操作。
not返回的值,一定是布尔值!
print(not 0) # True
print(not 3 > 2) # False
print(not 9 // 4) # False
print(not 'abc') # False进制表示
在 Python 中,不同进制的数,有不同的前缀:
- 二进制:以
0b或0B开头表示。 - 八进制:以
0o开头表示 - 十进制:无需前缀,正常编写即可。
- 十六进制:以
0x或0X开头表示,此处的A-F不区分大小写。
Python 中所有的『非十进制』数字,只是代码层面的编写方式,只是给程序员看的,Python 在进行:计算、打印等操作时,会自动将这些『非十进制』数字,转为『十进制』数字。
# 0b开头表示二进制
num1 = 0b11001
# 0o开头表示八进制
num2 = 0o1034
# 0x开头表示十六进制
num3 = 0x1cf
# Python 在对上面的 num1、num2、num3进行计算、打印等操作时,会自动将其转为十进制
print(num1, num2, num3) # 25 540 463
print(num1 + 1) # 26
print(str(num2)) # 540
print(num3 > 400) # True借助 Python 提供的内置函数,实现进制转换:
# 使用bin()将十进制转为二进制
result1 = bin(25)
# 使用oct()将十进制转为八进制
result2 = oct(540)
# 使用hex()将十进制转为十六进制
result3 = hex(463)
# 注意:bin() oct() hex()他们返回的值类型都是字符串
# 使用int()将指定进制的数,转为十进制数字
value1 = int('0b11001', 2)
value2 = int('0o1034', 8)
value3 = int('0x1cf', 16)输入语句
在 Python 中,输入语句用于:从键盘接收用户输入的内容。
# 使用input()获取用户的输入
name = input('请输入你的姓名:')
age = input('请输入你的年龄:')
# input()获取到的内容全都是字符串类型
# 不过我们可以手动进行数据类型转换。
print(type(age))
age = int(input('请输入你的年龄:'))第2章 流程控制语句
分支语句
if 判断条件1:
条件1【成立】时执行的代码
elif 判断条件2:
条件2【成立】时执行的代码
elif 判断条件3:
条件3【成立】时执行的代码
else: # else如不需要可以省略
上述所有条件都不成立时执行的代码一旦某个分支语句检测为
true,其他的elif以及else语句都将不再执行。
Python 3.10 引入的 match 表面上像 C中的 switch 语句,但其实它更像 Rust 中的模式匹配。
- 匹配顺序:按顺序匹配,第一个匹配的模式会被执行
- 通配符:
_是通配符,匹配任何值 - 变量绑定:在模式中可以使用变量来绑定值
match subject:
case pattern1:
# 处理 pattern1
case pattern2:
# 处理 pattern2
case _:
# 默认情况Python 的 match 语句提供了强大的模式匹配功能,可以:
- 匹配简单的值和多个值
- 匹配序列、映射和对象
- 使用守卫条件进行更复杂的匹配
- 提取和绑定变量
条件表达式
表达式:执行后最终能得到一个值的代码,就是表达式,例如这些都是表达式:
3 + 5
'abc' * 3
5 > 3
'y' in 'Python'
len('hello')条件表达式: 根据不同的条件,得到不同的值,又称三元表达式,也叫三目运算符。
# 什么时候适合用条件表达式?简单的二选一场景,可以让代码更紧凑。
rain = True food = '外卖' if rain else '出去吃'
is_vip = True disscount = 0.8 if is_vip else 1.0
is_login = True msg = '欢迎回来!' if is_login else '请先登录!'循环语句
while 循环:
while 循环条件:
条件成立时执行的操作1
条件成立时执行的操作2for 循环:
for 临时变量 in 可迭代对象:
要执行的操作1
要执行的操作2可迭代对象包括:range()函数、字符串、列表、元组、对象等等。
第3章 函数入门
Python 中函数分为三类:①内置函数、②模块提供的函数、③自定义函数。本章主要讲解自定义函数。
自定义函数内的第一条语句是字符串时,该字符串就是文档字符串,也称为 docstring。利用文档字符串可以自动生成在线文档或打印版文档,还可以让开发者在浏览代码时直接查阅文档。
def my_function():
"""第一行应为对象用途的简短摘要。为保持简洁,不要在这里显式说明对象名或类型
后面的行可包含若干段落,描述对象的调用约定、副作用等
"""
pass
print(my_function.__doc__)函数参数
- 位置参数:调用函数时,根据参数在函数定义时出现的顺序,把实参的值,依次传递给对应的形参。
- 关键字参数:函数调用时通过
形参名=值的形式传递的参数。同时有位置参数和关键字参数时,位置参数写在关键字参数前面,因为关键字参数不要求位置。
限制传参方式
/ 前面只能用『位置参数』,* 后面只能用『关键字参数』。
为了让代码易读、高效,最好限制参数的传递方式,这样,开发者只需查看函数定义,即可确定参数项是仅按位置、按位置或关键字,还是仅按关键字传递。
# 定义函数(使用/和*限制传参方式)
def greet(name, /, gender, *, age, height):
print(f'我叫{name},性别{gender},年龄是{age},身高是{height}cm')
greet('张三', '男', age=18, height=172)
greet('张三', gender='男', age=18, height=172)指定默认值
调用函数时,可以使用比定义时更少的参数。通过 形参名=值 的形式,为形参设置一个默认值,这样就可以实现:
- 若调用函数时没有传入该参数的值,就使用默认值。
- 若调用函数时传入该参数的值,就使用传入的值。
定义函数时,『默认参数』必须放在『必选参数』的后面,或者换一种说法就是:某个形参,一旦设置了默认值,那它后面的所有形参,也必须要写默认值!
# 定义函数(设置参数默认值的错误示例)
# def greet(name, gender, age, msg='你好', height):
# print(f'我叫{name},性别{gender},年龄是{age},身高是{height}cm')
# print(f'我想说:{msg}')默认值一般只计算一次,但当默认值为列表、字典或类实例等可变对象时,会产生与该规则不同的结果。例如,下面的函数会累积后续调用时传递的参数:
def f(a, L=[]):
L.append(a)
return L
print(f(1)) # [1]
print(f(2)) # [1, 2]
print(f(3)) # [1, 2, 3]不想在后续调用之间共享默认值时,需要每次给可变对象清空。
def f(a, L=None):
if L is None:
L = []
L.append(a)
return L可变参数
在定义函数时,如果不确定会传入多少个参数,那就可以使用可变参数,具体写法有两种:
- 使用
*形参名来接收任意数量的『位置参数』,多个位置参数最终会被打包成一个『元组』。 - 使用
**形参名来接收任意数量的『关键字参数』,多个关键字参数最终会被打包成一个『字典』。
# 定义函数(使用*args去接收:可变位置参数,args只是大家习惯这么写,可以换成其他变量)
def test1(*args):
# 此处args是元组
print(args)
test1('张三', '男', 18, 172)
# 定义函数(使用**kwargs去接收:可变关键字参数,kwargs只是大家习惯这么写,可以换成其他变量)
def test2(**kwargs):
# 此处kwargs是字典
print(kwargs)
test2(name='张三', gender='男', age=18, height=172)『可变位置参数』和『可变关键字参数』,可以同时使用,但必须要先写『可变位置参数』。
# 定义函数(同时使用:可变位置参数、可变关键字参数)
def test3(a, b, *args, c='尚硅谷', **kwargs):
pass
test3('张三', '男', '抽烟', '喝酒', age=18, height=172)特殊的字面量 None
None 是一个特殊的字面量,用来表示:空值、无值、无意义。
例如:msg = None 的含义是:先定义一个变量 msg,但目前还不知道它会存储什么类型的值。
None的类型是NoneType。None出现在布尔判断中(if判断条件、while循环条件),会被当作False来处理。None不能参与任何数学运算,也不能与字符串拼接。- 不给函数设置返回值,那函数默认就会返回
None
作用域
作用域就是变量能起作用的范围(变量在哪里能用,在哪里不能用)。
- 全局作用域:整个
.py文件最外层的范围,就是全局作用域。 - 全局变量:写在全局作用域中的变量,全局变量在整个程序中都可以访问。
- 局部作用域:函数的内部范围
- 局部变量:写在局部作用域中(函数内部)的变量,它只能在当前函数中使用。
- 在函数内部使用
global关键字,可以声明变量为全局变量。
- 在函数内部使用
函数说明文档
函数说明文档:写在函数里的文字说明,用来描述:函数的功能、需要哪些参数、返回什么结果,它的语法和普通字符串一样,用三引号包裹:
def add(n1, n2):
"""
计算两个数相加的结果
:param n1: 第一个数
:param n2: 第二个数
:return: 二者相加的结果
"""
return n1 + n2
result = add(1, 2)第4章 数据容器
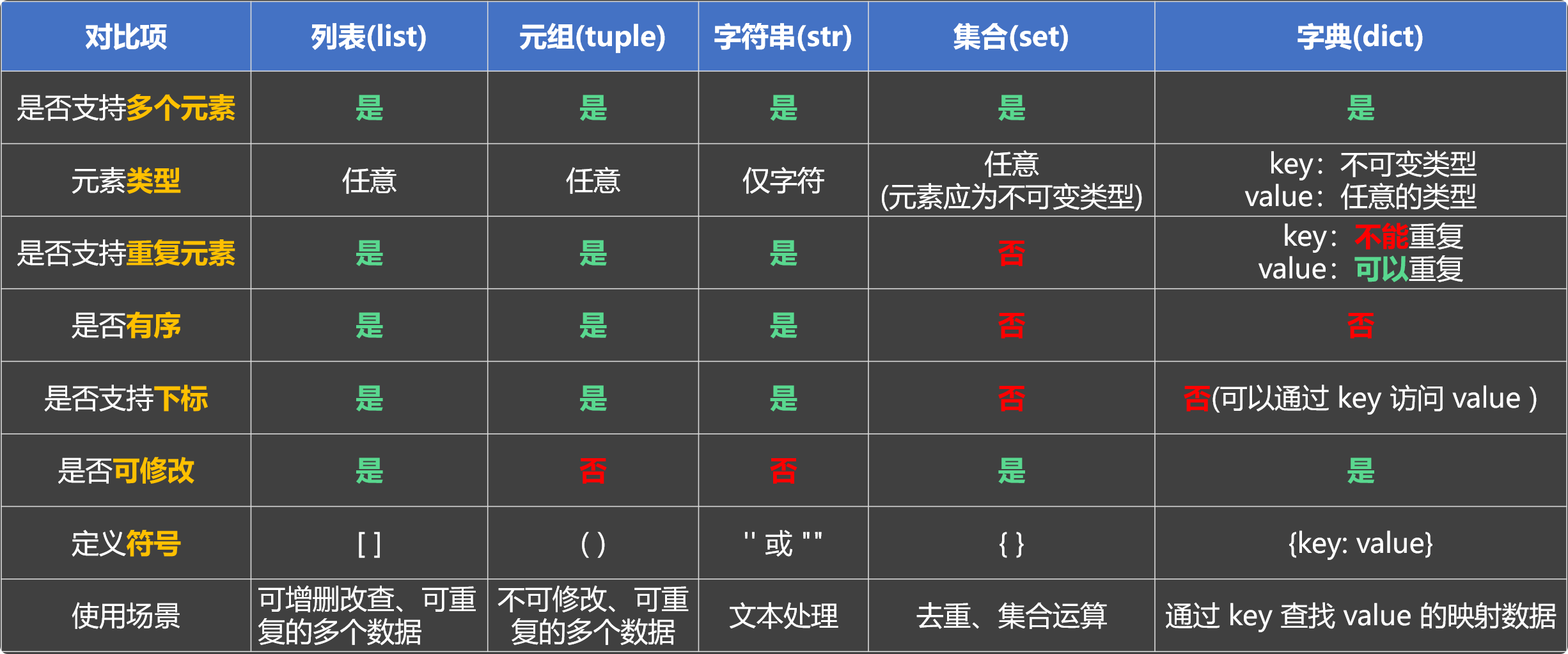
在 Python 中,用来存放多个数据的东西,就叫做『数据容器』。
数据容器的特点:
- 数据容器,有时也简称为容器。
- 数据容器可以存放多个数据,每个数据也被称为一个元素。
- 数据容器中的元素可以是任意类型。
- 数据容器会给我们提供多种操作元素的方法。
Python 中常用的数据容器:
- 列表(List)
- 元组(tuple)
- 字符串(str)
- 集合(set)
- 字典(dict)
列表
列表:用来存放一组有序的数据,并且可以对其中的数据进行:增删改查。
一句话总结:列表是最常用的数据容器,当遇到要“存储一批数据”的场景时,首选列表。
列表定义
# 定义有内容的列表
list1 = [34, 56, 21, 56, 11]
list2 = ['北京', '尚硅谷', '你好啊']
list3 = [23, '尚硅谷', True, None]
list4 = [23, '尚硅谷', True, None, [100, 200, 300]] # list4 是一个嵌套列表
# 定义空列表(列表中的数据,后期会通过特定写法填充)
list5 = []
list6 = list()列表增删改查
| 操作 | 写法 | 作用 |
|---|---|---|
| 新增 | 列表.append(元素) | 在列表尾部追加一个元素。 |
列表.insert(下标, 元素) | 在列表指定下标处添加一个元素。 | |
列表.extend(可迭代对象) | 将可迭代对象中的内容依次取出,追加到列表尾部。 | |
| 删除 | 列表.pop(下标) | 删除指定位置的元素,并将删除的元素返回。 |
列表.remove(值) | 删除列表中第一次出现的指定值。 | |
列表.clear() | 删除列表中的所有元素(清空列表)。 | |
del 列表[下标] | 删除指定位置的元素。 | |
| 修改 | 列表[下标] = 值 | 通过下标修改指定位置的元素。 |
| 查询 | 列表[下标] | 通过下标获取指定位置的元素。 |
列表的常用方法
除了上述的增删改查方法,列表中还有很多其他常用的方法:
| 写法 | 作用 | 返回值 |
|---|---|---|
列表.index(值) | 查找指定元素在列表中第一次出现的下标。 | 元素下标 |
列表.count(值) | 统计某个元素在列表中出现的次数。 | 元素出现的次数 |
列表.reverse() | 反转列表,无需参数,直接操作原列表。 | 无 |
列表.sort(reverse=布尔值) | 对列表排序(默认从小到大排列),会改变原列表,reverse 参数用于控制排序方式。 | 无 |
列表的循环遍历
# 定义一个成绩列表
score_list = [62, 50, 60, 48, 80, 20, 95]
# 使用while循环遍历列表
index = 0
while index < len(score_list):
print(score_list[index])
index += 1
# 使用for循环遍历列表
for item in score_list:
print(item)
# 使用for循环遍历列表(通过range函数 和 len函数按照索引遍历)
for index in range(len(score_list)):
print(score_list[index])
- 在上述遍历中,
while循环需要结束条件,所以我们定义了index变量。打印输出时,可以借助index输出当前元素是第几个。- 而
for循环的遍历,不需要index,那如果也想打印元素是第几个,但又不想去定义index的话,可以借助内置函数enumerate,它可以在遍历时获取索引和值,代码如下:
# 使用for循环遍历列表(通过enumerate函数,同时获取下标(索引值)和元素)
# enumerate 的 start 参数,可以让计数从指定值开始(改变的是循环时的“编号”,不是真正的索引值)
for index, item in enumerate(score_list, start=5):
print(index, item, score_list[0])
print('最后的打印', score_list[0])元组
元组:用来存放一组有序的数据,但其中的内容一旦创建就不可修改(不能增、删、改,只能查)。
由于元组不可变,所以元组不能使用append()、insert()这些方法,它里面的元素也不能被重新赋值。
一句话总结:元组是一种“只读”的数据容器,想保存一批“不会变的数据”时,首选元组。
元组定义
# 定义有内容的元组
# 使用方括号 () 来定义一个列表,用 , 去分隔不同的元素
t1 = (28, 67, 21, 67, 11)
t2 = ('北京', '尚硅谷', '你好')
t3 = (100, True, '你好', None)
t4 = (100, True, '你好', None, (50, 60, 70))
# 定义空元组
t1 = ()
t2 = tuple()
# 定义只有一个元素的元组
# 当元组中只有一个元素时,末尾必须写上 ,
t1 = ('你好',)
t2 = (18,)实际开发中的元组,不一定是我们自己定义的,比如函数的可变参数*args就是一个元组。
def demo(*args):
return sum(args)
result = demo(100, 200, 300)
print(result) # 600元组不可修改
元组中的元素,不可修改,但元组中如果存放了可变类型(如:列表),那可变类型中的内容仍可修改。
# 元组中的元素,不可修改
t1 = (28, 67, 21, 67, 11)
# t1[0] = 100
# 元组中的元素,不可修改,但元组中如果存放了可变类型(列表),那可变类型中的内容仍可修改
t2 = (28, 67, 21, 67, 11, [100, 200, 300, ('你好', '尚硅谷')])
t2[5][2] = 400
t2[5][3][0] = 'hello'元组的常用方法
由于元组不可修改,所以它的常用方法只有两个:
- 使用
元组.index(元素),获取指定元素在元组中第一次出现的下标。 - 使用
元组.count(元素),统计指定元素在元组中出现的次数。
元组的常用内置函数
元组的常用内置函数和列表一样,依然是这几个:max、min、len、sorted、sum。
注意:sorted 函数,对元组进行排序(不修改原元组,返回一个新的列表)
# sorted 函数,对元组进行排序(不修改原元组,返回一个新的列表)
t1 = (23, 11, 32, 30, 17)
result = sorted(t1, reverse=True)
print(tuple(result)) # (32, 30, 23, 17, 11)元组的循环遍历
元组的遍历与列表一样,可以使用while循环遍历,或for循环遍历。
解包列表或元组传参
解包列表、解包元组传参,就是把其中的元素依次取出,作为多个独立的参数传入函数。
# 定义函数时,使用*args(变量不一定非要用args,比如写:*data也行),将收到的多个参数,打包成一个元组
def test(*args):
print(f'我是test函数,我收到的参数是:{args},参数类型是:{type(args)}')
list1 = [100, 200, 300, 400]
tuple1 = ('你好', '北京', '尚硅谷')
# 函数调用时,正常传递:列表 或 元组
test(list1) # 参数是:([100, 200, 300, 400],),参数类型是:<class 'tuple'>
test(tuple1) # 参数是:(('你好', '北京', '尚硅谷'),),参数类型是:<class 'tuple'>
# 函数调用时,使用*对:列表 或 元组进行解包后,再传递参数
test(*list1) # 此种写法相当于:test(100, 200, 300, 400)
test(*tuple1) # 此种写法相当于:test('你好', '北京', '尚硅谷')字符串
字符串(str):用来存放一组有序的字符数据,但其中的内容不可修改(只能查,不能增删改)。
字符串定义
![[Python-基本语法#第1章 Python 核心基础##字符串]]
字符串不可修改,不可嵌套。
# 字符串中的字符,不可修改
msg = 'welcome to atguigu'
msg[0] = 'a'
# 字符串不能嵌套
msg = 'welcome to'hello' atguigu'
msg = 'welcome to"hello" atguigu'
msg = 'welcome to\'hello\' atguigu'字符串常用方法
| 写法 | 作用 | 返回值 |
|---|---|---|
字符串.index(值) | 查找指定元素在字符串中第一次出现的下标 | 元素下标 |
字符串.split(字符) | 将字符串按照『指定字符』进行分隔 | 新列表 |
字符串.replace(字符串片段) | 将字符串中的某个字符串片段,替换成目标字符串,不会修改原字符串 | 新字符串 |
字符串.count(字符) | 统计『指定字符』在字符串中出现的次数 | 下标 |
字符串.strip() | 从某个字符串中删除指定字符串中的任意字符,不会修改原字符串 | 新字符串 |
字符串常用内置函数
字符串也可以使用:max、min、len、sorted、sum函数,但实际开发中len函数最常用。
字符串的循环遍历
字符串的遍历,与列表一样,可以使用while循环遍历,或for循环遍历。
序列操作
序列是能连续存放元素的数据容器,而且元素有先后顺序,而且可以通过下标访问。我们学过的:列表、元组、字符串,都是序列。
序列的切片操作:从序列中按照指定范围,取出一部分元素,形成一个新的序列的操作。
语法格式为:序列[起始索引:结束索引:步长]
# 当起始索引大于结束索引时,步长必须为负数,否则结果是空列表。
list1 = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100]
list2 = list1[7:2:-1]
print(list2) # [80, 70, 60, 50, 40]
# 对元组进行切片
tuple1 = (10, 20, 30, 40, 50, 60, 70, 80, 90, 100)
tuple2 = tuple1[0:5:1]
print(tuple2) # (10, 20, 30, 40, 50)
# 对字符串进行切片
msg1 = 'welcome to atguigu'
msg2 = msg1[2:9:2]
print(msg2) # loet序列相加: 把两个序列拼接在一起。注意:只有同类型的序列才能相加(字符串+字符串、列表+列表、元组+元组)。
# 列表相加
list1 = [10, 20, 30, 40]
list2 = [50, 60, 70, 80]
list3 = list1 + list2
print(list3) # [10, 20, 30, 40, 50, 60, 70, 80]序列相乘(重复):把序列重复指定的次数。
# 序列相乘(重复)
list1 = [10, 20, 30, 40]
list2 = list1 * 3
print(list2) # [10, 20, 30, 40, 10, 20, 30, 40, 10, 20, 30, 40]集合
集合分为两种,分别是:
- 可变集合(set):内部的元素无序、不能通过下标访问元素、会自动去除重复元素。
- 不可变集合(forzenset):特点和可变集合一样,唯一的区别就是:其中的元素不可修改。
一句话总结:集合是可以去重的数据容器,当只关心元素是否存在,而不在乎顺序的时,首选集合。
集合定义
可变集合的定义方式:使用花括号{}包裹,不同的数据项之间,用,做分隔。
# 定义有内容的【可变集合】
s1 = {10, 20, 20, 30, 40, 40, 50, 60, 60, 70, 80, 90, 100}
s2 = {'你好', 'hello', '你好', 'atguigu', '北京'}
s3 = {10, '你好', True, 1, 12.4}
# 定义空集合(可变集合)
s1 = set()不能直接写
{}来定义空集合,因为直接写{}定义的是:空字典。
不可变集合的定义方式:借助内置的forzenset函数。
# 定义有内容的【不可变集合】
s1 = frozenset({10, 20, 20, 30, 40, 40, 50, 60, 60, 70, 80, 90, 100})
s2 = frozenset({'你好', 'hello', '你好', 'atguigu', '北京'})
s3 = frozenset({10, '你好', True, 1, 12.4})
# 定义空集合(不可变集合)
s3 = frozenset()
print(type(s3), s3)
# frozenset 接收的参数,可以是任意可迭代对象,但最终返回的一定是【不可变集合】
s1 = frozenset([10, 20, 30, 40, 50])
s2 = frozenset((10, 20, 30, 40, 50))
s3 = frozenset('hello')集合中不能嵌套【可变集合】,但可以嵌套【不可变集合】。
# 通俗理解:只有“不可变”的东西,才能安全的放进集合里
s1 = {10, 20, 30, 40, 50}
s2 = frozenset({100, 200, 300, 400, 500})
l1 = [666, 777, 888]
t1 = ('hello', 'atguigu', '北京')
s3 = {11, 22, 33, s1} # 报错
s3 = {11, 22, 33, s2} # 没问题
s3 = {11, 22, 33, l1} # 报错
s3 = {11, 22, 33, t1} # 没问题集合增删改查
| 操作 | 写法 | 作用 |
|---|---|---|
| 新增 | 集合.add(元素) | 向集合中添加一个元素。 |
集合.update(可迭代对象) | 将可迭代对象中的内容依次取出,添加到集合中。 | |
| 删除 | 集合.pop() | 从集合中移除一个任意元素,并将删除的元素返回。 |
集合.remove(元素) | 从集合中移除指定元素(若元素不存在,会报错) | |
集合.discard(元素) | 从集合中移除指定元素(若元素不存在,不会报错) | |
集合.clear() | 清空集合 | |
| 修改 | remove + add的组合 | |
| 查询 | 集合不能通过下标去读取元素 | 但能通过 【成员运算符】去查看集合中是否包含指定元素 |
集合常用方法
| 写法 | 作用 | 返回值 |
|---|---|---|
集合A.difference(集合B) | 找出集合A中,不同于集合B的元素 | 新集合 |
集合A.difference_update(集合B) | 从集合A中,删除集合B中存在的元素 | None |
集合A.union(集合B) | 合并两个集合 | 新集合 |
集合A.issubset(集合B) | 判断集合A是否为集合B的子集 | 布尔值 |
集合A.issuperset(集合B) | 判断集合A是否是集合B的超集 | 布尔值 |
集合A.isdisjoint(集合B) | 判断集合A和集合B是否没有交集 | 布尔值 |
集合的数学运算
s1 = {10, 20, 30, 40, 50, 60}
s2 = {40, 50, 60, 70, 80, 90}
# 并集
result = s1 | s2
# 交集
result = s1 & s2
# 差集
result = s1 - s2
# 对称差集
result = s1 ^ s2集合的循环遍历
由于集合不支持下标,所以集合不能使用 while 循环遍历,可以使用for循环遍历。
字典
字典:用来存放一组『键值对』数据,可通过『键(key)』对『值(value)』进行:增、删、改、查操作。
- 键唯一:字典中的键(key)不能重复,若重复则后写的会覆盖前写的。
- 键不可变:键必须是不可变类型(如数字、字符串、元组等),而值可以是任意类型。
一句话总结:字典是一种以“键”找“值”的映射型容器,当需要唯一标识 → 对应信息的结构时,首选字典。
字典定义
用大括号{}包裹,每个元素之间用逗号,分隔,每个元素的格式为key:value。
# 定义有内容的字典
d1 = {'张三': 72, '李四': 60, '王五': 85}
# 字典中的key不能重复,若出现重复,则后写的会覆盖之前写的
d1 = {'张三': 72, '李四': 60, '王五': 85, '张三': 99}
# 定义空字典
d1 = {}
d2 = dict()字典中的 key 必须是不可变类型,但 value 可以是任意类型。
字典增删改查
| 操作 | 写法 | 作用 |
|---|---|---|
| 新增 | 字典[key] = 值 | 向字典中添加一个元素。 |
| 删除 | 字典.pop(key) | 删除指定key所对应的那组键值对,并返回key所对应的值 |
del 字典[key] | 删除指定key所对应的那组键值对 | |
字典.clear() | 清空字典 | |
| 修改 | 字典[key] = 值 | 与新增的写法一样,若字典中有对应的key,就是修改 |
字典.update(字典) | 批量修改 | |
| 查询 | 字典[key] | 直接取值,若key不存在,会报错 |
字典.get(key, 默认值) | 安全取值,若key不存在,会返回默认值(若没有设置默认值,则返回None) |
# 删除
d1 = {'张三': 72, '李四': 60, '王五': 85}
# pop方法可以设置默认值
# 默认值可以保证:当要删除的key不存在的情况下,程序不会报错,并且返回这个默认值
result = d1.pop('奥特曼', '删除失败!')字典的常用方法
使用keys方法,获取字典中所有的键。
# keys方法:用于获取字典中所有的键
d1 = {'张三': 72, '李四': 60, '王五': 85}
# keys方法的返回值不是list,而是一种叫做dict_keys的类型
result = d1.keys()
print(result)
print(type(result))
# dict_keys和列表类似,可以被遍历,但要注意的是:它不能通过下标访问元素
for item in result:
print(item)
# 借助内置的list函数,可以将dict_keys转换成list
l1 = list(result)使用values方法,获取字典中所有的值。
# values方法的返回值类型是:dict_values,它的特点和dict_keys一样
result = d1.values()使用items方法,获取字典中所有的键值对(每组键值对以元组的形式呈现)。
# items方法返回的类型是:dict_items,它的特点也和dict_keys一样
result = d1.items()字典的循环遍历
字典不能使用while循环遍历,但可以使用for循环遍历。
d1 = {'张三': 72, '李四': 60, '王五': 85}
for key in d1:
print(f'{key}的成绩是{d1[key]}')
for key in d1.keys():
print(f'{key}的成绩是{d1[key]}')items()可以同时提取键及其对应的值enumerate()可以同时取出位置索引和对应的值- 同时循环两个或多个序列时,
zip()函数可以将其内的元素一一匹配
for key, value in d1.items():
pass
for index, value in enumerate(d1):
pass
for q, a in zip(questions, answers):
pass数据容器_通用操作
| 写法 | 作用 | 返回值 |
|---|---|---|
sorted(数据容器, reverse=布尔值) | 对容器排序(默认从小到大排列)不会改变原列表,reverse 参数用于控制排序方式。 | 排序后的新容器 |
len(数据容器) | 获取容器中元素的总数量。 | 元素总数量 |
max(数据容器) | 获取容器中的最大值。 | 最大值 |
min(数据容器) | 获取容器中的最小值。 | 最小值 |
sum(数据容器) | 获取容器中所有元素的和。⚠️ 字符串不能使用 sum | 所有元素的和 |
sorted()vs.sort():sorted()是产生新容器(原件不动),而前面的.sort()是直接修改原容器。
除了上述这些内置函数以外,数据容器都可以进行如下通用操作
list函数: 1.定义空列表;2.将【可迭代对象】转换为列表。tuple函数:1.定义空元组;2.将【可迭代对象】转换为元组。set函数: 1.定义空集合;2.将【可迭代对象】转换为集合。str函数: 1.定义空字符串;2.将【任意类型】转换为字符串。dict函数: 1.定义空字典;2.将【可迭代对象】转换为字典。- 所有的数据容器,都支持【成员运算符】
in / not in作用:判断某个元素是否在于容器中。