Python-面向对象
前言
学习尚硅谷的《python零基础教程》的第89到135分集。
结合了部分Python 官方的 Python3 tutorial 中文版 。
第5章 面向对象
『对象』是一个拥有『属性』和『行为』的个体,它是构成现实世界和程序世界的基本单位。
- 类(class)是用来描述一类事物的"模板",它规定了一类事物所具有的『属性』和『行为』。
- 实例:根据『类』创建出来的一个具体的『对象』又称『实例』,也可称为『实例对象』。
类是抽象的“模板”,『实例 / 实例对象 / 对象』是具体的个体。
类的定义
定义一个类(类名通常用大驼峰写法),如:Person、UserInfo。
class 类名:
# 当一个函数被定义在类中时,它就被称为“方法”。
# __init__方法又叫:初始化方法,它主要用来给当前实例对象添加属性。
# __init__方法收到的参数是:当前正在创建的实例对象、其他自定义参数。
def __init__(self, 参数1, 参数2, 参数3):
# 通过self给当前实例添加属性,语法格式为:self.属性名 = 属性值
self.属性名 = 参数1
self.属性名 = 参数2
self.属性名 = 参数3
__init__方法叫初始化方法,当我们对类进行实例化时,Python会自动调用__init__方法。__init__方法的名字不能更改,否则 Python 无法自动调用。__init__收到的第一个参数是当前正在创建的实例对象,形参通常用self。__init__方法收到的除self以外的参数,通常用来设置实例的属性值,通过“点”语法实现:self.属性名 = 属性值。
创建实例
语法格式:
实例名 = 类名(参数1, 参数2, ...)通过 实例.__dict__ 的方式,可以查看实例身上的所有属性。
p1 = Person('张三', 18, '男')
print(p1.__dict__) # 打印对象自己身上的东西
# {'name': '张三', 'age': 18, 'gender': '男'}
print(dir(p1)) # 打印对象能访问到的东西
# ['__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__firstlineno__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__static_attributes__', '__str__', '__subclasshook__', '__weakref__', 'age', 'gender', 'name']在实例创建完毕后,也可以通过实例.属性名 = 值的形式,给实例追加属性(有则修改,无则添加)。
p1.address = '北京昌平宏福科技园'
print(p1.__dict__)通过type() 函数,可以查看某个实例对象,是由哪个类创建出来的。
print(type(p1))
print(type(p2))自定义方法
通过 self.属性名 = 值的形式,为实例对象添加了『属性』;通过『自定义方法』,让对象具备相应的『行为』。
# 定义一个Person类
class Person:
# 初始化方法(给实例添加属性)
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# 自定义方法(给实例添加行为)
# speak方法收到的参数是:调用speak方法的实例对象(self)、其它参数
# speak方法只有一份,保存在Person类身上的,所有Person类的实例对象,都可以调用到speak方法
def speak(self, msg):
print(f'我叫{self.name}, 年龄是{self.age}, 性别是{self.gender},我想说:{msg}')『自定义方法』的第一个参数也是self,是调用该方法的实例对象。
# 创建Person类的实例对象
p1 = Person('张三', 18, '男')
print(p1.speak) # 方法对象
print(Person.speak) # 函数对象
# <bound method Person.speak of <__main__.Person object at 0x7fc301796660>>
# <function Person.speak at 0x7fc30fd2b1a0>
p1.speak('实例.speak')
Person.speak(p1, '类.speak')方法对象的特殊之处在于,实例对象会作为函数(speak())的第一个参数被传入,比如调用 p1.speak() 相当于调用 Person.speak(p1)(这里的实参 p1 就是 __init__() 中的形参 self )。
类属性和实例属性
实例属性用于每个实例的唯一数据,而类属性用于类的所有实例共享的属性和方法:
class Dog:
# 类属性被所有实例所共享
# 类属性通常用于保存:公共数据
kind = 'canine'
def __init__(self, name):
self.name = name # 实例属性为每个实例所独有共享数据在涉及 mutable 对象,例如列表和字典,会有令人惊讶的结果。 例如以下代码中的 tricks 列表不应该被用作类变量,因为所有的 Dog 实例将只共享一个单独的列表:
class Dog:
tricks = [] # 类属性的错误用法
def __init__(self, name):
self.name = name
# self.tricks = [] # 正确用法:为每个 Dog 实例新建一个空列表
def add_trick(self, trick):
self.tricks.append(trick)实例方法和类方法
实例方法:类中所定义的方法,最终会保存在类身上,并且主要是通过实例调用。
- 实例方法虽然最终会保存在类身上,但它主要是供实例使用的,所以才叫实例方法。
- 因为收到了
self参数,所以其内部可以:访问实例属性,调用实例方法。 - 实例方法的主要作用:定义实例对象的具体行为。
类方法:使用@classmethod装饰器修饰,第一个参数是类本身,通常用形参cls接收。
- 因为收到了
cls参数,所以类方法内部可以访问类属性。 - 一般用于:实现与类相关的逻辑,如:操作类级别的信息、工厂方法等。
# 定义一个Person类
class Person:
# 类属性
max_age = 120
planet = '地球'
# 初始化方法(给实例添加属性)
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# speak方法、run方法,他们都属于:实例方法
def speak(self, msg):
print(f'我叫{self.name}, 年龄是{self.age}, 性别是{self.gender},我想说:{msg}')
def run(self, distance):
print(f'{self.name}疯狂的奔跑了{distance}米')
# 使用 @classmethod 装饰过的方法,就叫:类方法,类方法保存在类身上的
# 类方法收到的参数:当前类本身(cls)、自定义的参数
@classmethod
def change_planet(cls, value):
cls.planet = value静态方法
定义:使用@staticmethod装饰器修饰,方法没有self或cls参数,只是单纯的定义在类中。
- 由于没有
self或cls参数,所以静态方法中通常:不访问类属性,也不访问实例属性。 - 一般用于:定义与类相关,但可以独立使用的工具方法。
# 定义一个Person类
class Person:
# *******************************
# *******************************
# *******************************
# 静态方法
# 使用 @staticmethod 装饰过的方法,就叫:静态方法,静态方法也是保存在类身上的
@staticmethod
def is_adult(year):
# 获取当前的年份
current_year = datetime.now().year
# 计算年龄
age = current_year - year
# 返回结果(成年True,未成年False)
return age >= 18
@staticmethod
def mask_idcard(idcard):
return idcard[:6] + '********' + idcard[-4:]继承
继承:是指一个类,可以继承另一个类的属性和方法。
# 定义一个Person类
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
def speak(self, msg):
print(f'我叫{self.name}, 年龄是{self.age}, 性别是{self.gender},我想说:{msg}')
# 定义一个Student类(子类、派生类), 继承自Person类(父类、超类、基类)
class Student(Person):
def __init__(self, name, age, gender, stu_id, grade):
# 在子类中,有两种方式去调用父类的初始化方法,来实现对继承属性
# 方式1(更推荐)
super().__init__(name, age, gender)
# 方式2 继承多个类的初始化时,会用到
# Person.__init__(self, name, age, gender)
# 子类独有的属性,需要自己手动完成初始化
self.stu_id = stu_id
self.grade = grade
def study(self):
print(f'我叫{self.name},我在努力的学习,争取做到{self.grade}年级的第一名')
- 定义类时,在类名后写圆括号
(),并填入另一个类名,表示该类继承自另一个类。- 在子类中,可以直接使用父类中定义的:属性、方法,也可以定义自己独有的内容。
super().__init__()的作用:调用父类的初始化方法。
如果子类中定义了与父类同名的方法,则会子类会“覆盖”父类中的方法,又称:方法重写。
# 定义一个Student类,继承自Person类
class Student(Person):
def __init__(self, name, age, gender, stu_id, grade):
super().__init__(name, age, gender)
self.stu_id = stu_id
self.grade = grade
# 方法重写:当子类中定义了一个与父类中相同的方法,那么子类中的方法就会“覆盖”父类的方法
def speak(self, msg):
super().speak(msg)
print(f'我是学生,我的学号是{self.stu_id},我正在读{self.grade},我想说:{msg}')Python 有两个内置函数可被用于继承机制:
| 函数 | 作用 |
|---|---|
isinstance(obj, Class) | 判断对象是否为指定类或其子类的实例 |
issubclass(Sub, Super) | 判断一个类是否是另一个类的子类 |
多重继承指一个类同时继承多个父类,从而拥有多个父类的属性和方法。搜索从父类所继承属性的操作是深度优先、从左到右的,当存在重复时不会在同一个类中搜索两次。
# 定义一个Student类,继承自:Person类、Worker类
class Student(Person, Worker):
def __init__(self, name, age, gender, stu_id, grade, company):
Person.__init__(self, name, age, gender)
Worker.__init__(self, company)
self.stu_id = stu_id
self.grade = grade
def study(self):
print(f'我在很努力的学习,争取做{self.grade}年级的第一名')类的__mro__属性:用于记录属性和方法的查找顺序。
# 通过实例去查找属性或方法时,会现在实例自身上寻找,如果没有,就按照__mro__中所记录的顺序去查找
print(Student.__mro__)
# (<class '__main__.Student'>, <class '__main__.Worker'>, <class '__main__.Person'>, <class 'object'>)权限控制
三种权限
在 Python 中,我们可以给属性赋予三种权限,分别是:公有属性、受保护属性、私有属性。
| 权限类型 | 定义方式 | 在当前类内部访问 | 在子类内部访问 | 在类外部访问 |
|---|---|---|---|---|
| 公有属性 | 属性名 | ✅ 能 | ✅ 能 | ✅ 能 |
| 受保护属性 | _属性名 | ✅ 能 | ✅ 能 | ⚠️ 能(但不推荐) |
| 私有属性 | __属性名 | ✅ 能 | ❌ 不能 | ❌ 不能 |
class Person:
def __init__(self, name, age, idcard):
self.name = name # 公有属性:当前类内部、子类内部、类外部,可都可访问
self._age = age # 受保护属性:当前类内部、子类内部,可以访问
self.__idcard = idcard # 私有属性:仅能在当前类内部访问
def speak(self):
# 类的内部,可以访问任何权限的属性(公有属性、受保护属性、私有属性)。
print(f"我叫:{self.name},年龄:{self._age},身份证:{self.__idcard}")
class Student(Person):
def hello(self):
# 子类的内部可以访问:公有属性、受保护属性
print(f"我是学生,我叫:{self.name},年龄:{self._age}")Python 不存在私有的实例变量。Python保护【私有属性】的方式,是重命名,也叫名称改写。例如
__idcard属性,会被重命名为:_Person__idcard。
getter 与 setter
在面向对象编程中,我们会把一些内部数据保护起来,但同时还想提供一个“安全的通道”让外部访问。这时候我们就用到:
- getter:读取属性的方法
- setter:修改属性的方法
在 Python 中:通过 @property 和 @xxx.setter 语法,把普通方法变成像属性一样使用的方法。
class Person:
def __init__(self, name, age):
self.name = name
self._age = age
# 注册 age 属性的 getter 方法:当访问 Person 实例的 age 属性时,age方法会自动调用
@property
def age(self):
return self._age
# 注册 age 属性的 setter 方法:当给 Person 实例的 age 属性赋值时,age方法会自动调用
@age.setter
def age(self, value):
if value <= 120:
self._age = value
else:
print('年龄非法,已将年龄变为最大值120')
self._age = 120
p1 = Person('张三', 18, '110101199001011234')
p1._age = 19 # setter
print(p1.age) # getter魔法方法
魔法方法是以 __xxx__命名的特殊方法(双下划线开头和结尾)。
- 魔法方法不需要手动调用,在特定场景由 Python 自动调用。
几个常用的魔法方法:
| 方法 | 调用时机 |
|---|---|
__str__ | 当调用 print(对象)或str(对象) 时 |
__len__ | 当调用len(对象)时 |
__lt__ | 当执行对象1 < 对象2时 |
__gt__ | 当执行对象1 > 对象2时 |
__eq__ | 当执行对象1 == 对象2时 |
__getattr__ | 当访问不存在的属性时 |
class Person:
def __init__(self, name, age, gender):
self.name = name
self.age = age
self.gender = gender
# __str__ 方法,执行时机:当调用 print(对象)或str(对象) 时
def __str__(self):
return f'姓名:{self.name}, 年龄:{self.age}, 性别:{self.gender}'
# __len__ 方法,执行时机:当调用len(对象)时
def __len__(self):
return len(self.__dict__)
# __lt__方法,执行时机:当执行 对象1 < 对象2 时
def __lt__(self, other):
return self.age < other.age
# __gt__方法,执行时机:当执行 对象1 > 对象2 时
def __gt__(self, other):
return self.age > other.age
# __eq__方法,执行时机:当执行 对象1 == 对象2 时
def __eq__(self, other):
return self.__dict__ == other.__dict__
# __getattr__方法,执行时机:当访问了对象不存在的属性时
def __getattr__(self, item):
print(f'您访问的{item}属性,不存在!')多态
多态就是“多种形态”,即:不同的对象调使用同一个方法名调用方法时,会表现出不同的行为。
Python 支持两种多态:
- 标准多态,基于继承实现多态。常见于
Java、C++这样的强类型语言中。 - 鸭子多态,不需要继承,只要传进来的对象,有对应实现就可以。
[!info] 鸭子类型
如果一个东西看起来像鸭子,叫起来也像鸭子,那它就是鸭子,鸭子类型指一种编程风格,它并不依靠查找对象类型,来确定其是否具有正确的实现,而是直接调用或使用其方法或属性。
class Animal:
def speak(self):
print('动物正在发出声音')
class Dog(Animal):
def speak(self):
print('汪汪汪!')
class Cat(Animal):
def speak(self):
print('喵喵喵!')
# 注意Pig类没有继承Animal类
class Pig:
def speak(self):
print('哼哼哼!')
# make_sound函数要求:传入的对象,必须是 Animal 类型(或其子类型),才能保证可以调用到speak方法
def make_sound(animal:Animal):
animal.speak()
# 多态的体现:同一函数,不同对象 → 不同行为
make_sound(Animal()) # 动物正在发出声音
make_sound(Dog()) # 汪汪汪!
make_sound(Cat()) # 喵喵喵!
# 按标准多态规则:Pig 没有继承 Animal,类型不匹配(会出现类型警告)
p1 = Pig()
make_sound(p1) # 在其它语言中会报错,虽然 Python 中能运行,但这不属于标准多态,属于鸭子多态鸭子多态不限制 make_sound 函数的传入对象类型。
抽象类
抽象类是一种不能被直接实例化的类,通常作为“规范”,让子类去继承并实现其中定义的抽象方法,本身只定义规范,不需要提供完整实现。
from abc import ABC, abstractmethod
# MustRun类一旦继承了ABC类,那MustRun类就是【抽象类】了
class MustRun(ABC):
# run方法一旦被@abstractmethod装饰后,就变成了【抽象方法】
@abstractmethod
def run(self):
pass第6章 函数进阶
函数也是对象
- 函数也是对象。
a1 = 100 # a1是int类的实例对象
a2 = 'hello' # a2是str类的实例对象
a3 = [10, 20, 30] # a3是list类的实例对象
def welcome(): # welcome函数是function类的实例对象
print('你好啊')
print(type(a1)) # <class 'int'>
print(type(a2)) # <class 'str'>
print(type(a3)) # <class 'list'>
print(type(welcome))# <class 'function'>- 函数可以像对象一样,动态添加属性。
def welcome():
print('你好啊')
welcome.desc = '这是一个打招呼的函数'
welcome.version = 1.0
print(welcome.__dict__) # {'desc': '这是一个打招呼的函数', 'version': 1.0}- 函数可以赋值给变量。
def welcome():
print('你好啊!')
# 把函数对象赋值给变量
say_hello = welcome
# 通过变量调用函数
say_hello()
# 通过函数名调用函数
welcome()- 函数也可以作为参数
def welcome():
print('你好啊!')
def caller(f):
print('caller函数开始调用')
f()
caller(welcome)- 函数也可以作为返回值
def welcome():
print('你好啊')
def show_msg(msg):
print(msg)
return show_msg
# result = welcome()
# result('尚硅谷')
welcome()('尚硅谷')[!info] 高阶函数
当一个函数的『参数是函数』或者『返回值是函数』,那该函数就是『高阶函数』。
高阶函数的意义有:
- 代码复用性高:可以把行为“独立出去”,传入不同函数实现不同逻辑。
- 能让函数更灵活,更通用。
- 高阶函数是:装饰器、闭包的基础。
# 关于高阶函数的前两点意义
def info(msg):
return '[提示]' + msg
def warn(msg):
return '[警告]' + msg
def error(msg):
return '[错误]' + msg
def log(fun, text):
print(fun(text))
log(info, '文件保存成功!')
log(warn, '磁盘空间不足!')
log(error, '该用户不存在!')函数的多返回值
在return关键字后面写多个值,并且多个值之间用逗号隔开,Python 会自动把多个值打包成元组。
def calculate(x, y):
res1 = x + y
res2 = x - y
return res1, res2 # 实际返回的是:(res1, res2)
result = calculate(10, 20)
r1, r2 = calculate(10, 20)参数打包与解包
定义函数时,打包接收参数:
*形参名:打包所有的位置参数(会形成一个元组)。**形参名:打包所有的关键字参数(会形成一个字典)。
调用函数时,解包传递参数:
*变量名:将元组拆解成一个个独立的位置参数。**变量名:将字典拆解一个个key=value形式的关键字参数。
def show_info(*args, **kwargs):
print(args)
print(kwargs)
nums = (10, 20, 30)
person = {'name': '张三', 'age': 18}
show_info(*nums, **person)匿名函数
匿名函数,是没有名字的函数,它无需使用def关键字去定义。Python 中使用lambda关键字来定义匿名函数。
- 格式为:
lambda 参数: 表达式。 - 只能写一行,不能写多行代码。
- 不能写代码块(if、for、while),但可以结合条件表达式使用
- 冒号右边必须是表达式,且只能写一个表达式。
- 执行结果自动作为返回值。
def add(x, y):
return x + y
def sub(x, y):
return x - y
def calculate(func, a, b):
print(f'计算结果为:{func(a, b)}')
# 使用普通函数实现计算效果
calculate(add, 30, 10)
calculate(sub, 30, 10)
# 使用匿名函数实现计算效果
calculate(lambda x, y: x + y, 30, 10)
calculate(lambda x, y: x - y, 30, 10)数据处理函数
| 函数 | 功能 |
|---|---|
map(操作函数, iterbale) | 对一组数据中的每一个元素,统一执行某种操作(加工),并生成一组新数据。 |
filter(过滤函数, iterable) | 从一组数据中,筛选出符合条件的元素(过滤),并组成一组新数据。 |
sorted(iterable, key=xxx, reverse=xxx) | 对一组数据进行排序,返回一组新数据。 |
reduce(合并函数, iterbale, 初始值) | 将一组数据不断“合并”,最终归并成一个结果。 |
# map(): 统一数据处理
nums = [10, 20, 30, 40]
# map函数的返回值是一个迭代器对象,需要我们自己去手动遍历,或者手动类型转换
result = map(lambda x: x * 2, nums)
print(list(result)) # [20 40 60 80]
print(nums) # [10 20 30 40]
# 注意点:
# 1.延迟执行:map 不会立刻计算,只有在“需要结果”时才执行计算。
# 2.返回的是迭代器对象,且一旦遍历完成,就会被“耗尽”。
# 3.map不会影响元素数量。# 筛选数值
nums = [10, 20, 30, 40, 50]
result = filter(lambda n: n > 30, nums)
print(list(result)) # [40 50]
print(nums) # [10 20 30 40 50]
# filter函数的特殊用法:如果不传递过滤函数,那么自动会过滤掉“假值”
data = [0, 1, '', 'hello', [], (), 5]
result = filter(None, data)
print(list(result)) # [1 'hello' 5]
# 注意点
# 1.延迟执行:filter不会立刻筛选,只有在“需要结果”时才执行。
# 2.返回的是迭代器对象,且一旦遍历完成就会被“耗尽”。
# 3.filter可能会影响元素数量。# 数字排序
nums = [30, 40, 20, 10]
result = sorted(nums, reverse=True)
print(result)
# 按照字符串的长度去排序
names = ['python', 'sql', 'java']
result = sorted(names, key=len, reverse=True)
print(result)# 从 functools 模块中引入 reduce
from functools import reduce
# 数值统计
nums = [1, 2, 3, 4, 5]
result = reduce(lambda a, b: a + b, nums, 10)
print(result) # 25,即 10 + 1 + 2 + 3 + 4 + 5
# 字符串拼接
str_list = ['ab', 'cd', 'ef']
result = reduce(lambda a, b: a + b, str_list)
print(result) # 'abcdef'列表推导式
- 概念:用一条简洁语句,从可迭代对象中,生成新列表的语法结构。
- 语法格式:
[ 表达式 for 变量 in 可迭代对象 ]
# 需求:让nums列表中所有的元素,都变为原来的2倍
# 方式一:用map函数
nums = [10, 20, 30, 40]
result = list(map(lambda n: n * 2, nums))
print(result)
# 方式二:使用列表推导式(列表推导式就是 for + append 的简写形式)
nums = [10, 20, 30, 40]
result = [n * 2 for n in nums]
print(result)
# 带条件的列表推导式
nums = [10, 20, 30, 40]
result = [n * 2 for n in nums if n > 20]
print(result)其他推导式:
# 字典推导式
names = ['张三', '李四', '王五']
scores = [60, 70, 80]
result = {names[i]: scores[i] for i in range(len(names))}
print(result)
# 集合推导式
names = ['张三', '李四', '王五']
result = {n + '!' for n in names}
print(result)
names = ['张三', '李四', '王五']
# 注意:Python中没有元组推导式,下面这种写法叫:生成器
result = (n + '!' for n in names)
print(result) # <generator object <genexpr> at 0x7ff217c7fd30>浅拷贝与深拷贝
浅拷贝会创建一个新的外层容器,但内部的元素仍然引用原来的对象。
- 存在的问题:嵌套数据仍然是共享的,修改嵌套数据会互相影响。
深拷贝创建一个新的外层容器,同时对内部所有【可变对象】进行递归复制(不可变对象不复制,继续引用)。
- 深拷贝可以彻底消除数据之间的相互影响。
- 深拷贝只复制可变对象,不可变对象会直接引用。
- 元组中如果只包含不可变对象,则深拷贝没有效果,会直接引用元组。
import copy
nums1 = [10, 20, 30, [40, 50]]
# 浅拷贝
nums2 = copy.copy(nums1)
# 深拷贝
nums2 = copy.deepcopy(nums1)
nums2[3][0] = 99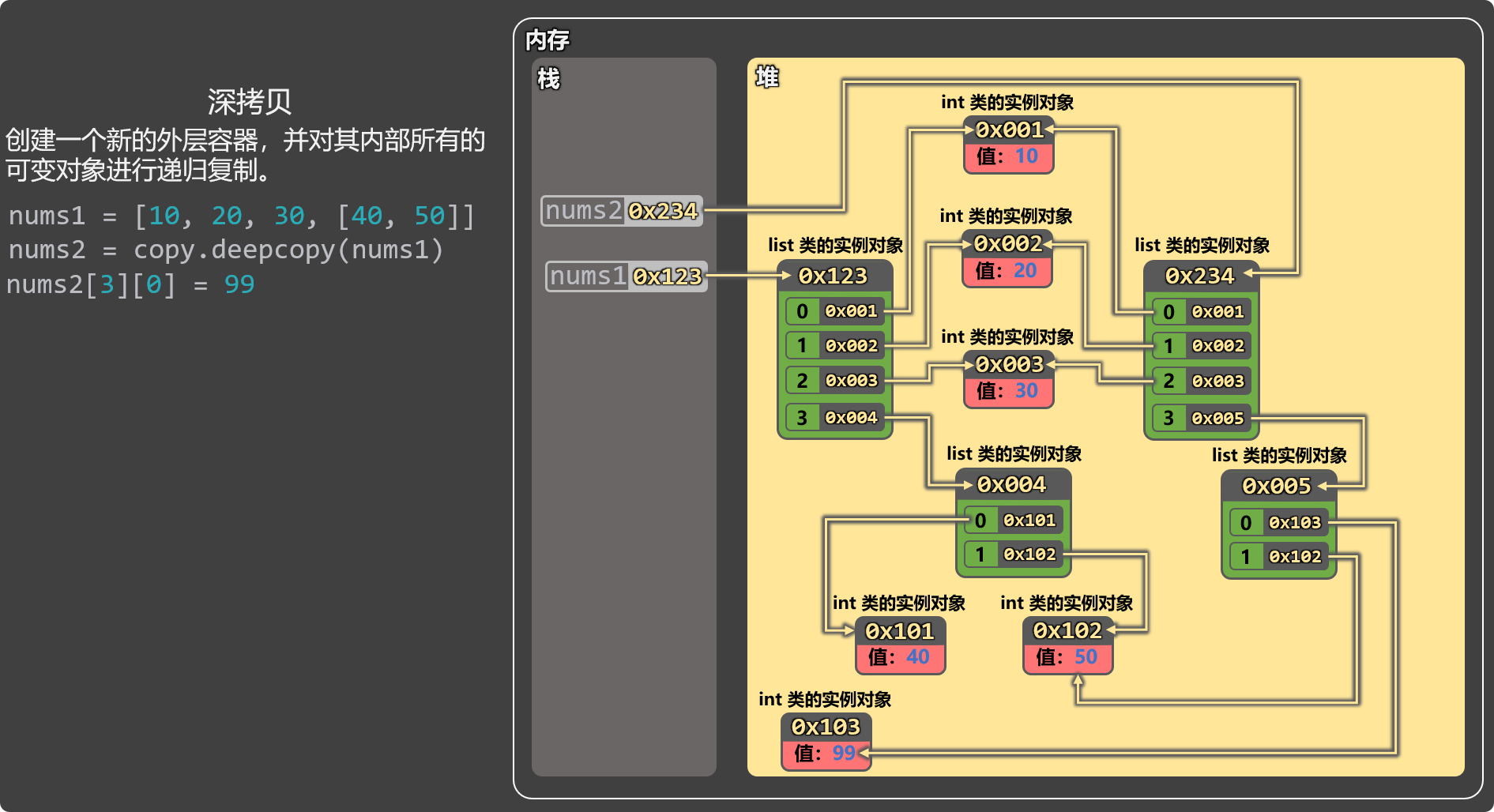
作用域
Python 的作用域规则(LEGB):
- L (Local):局部作用域,在函数内部定义。
- E (Enclosing):嵌套函数的外层函数作用域,即外层作用域。
- G (Global):模块级别(
.py文件)的作用域,即全局作用域。 - B (Built-in):Python 内建作用域。
当访问一个变量时,Python 会按以下顺序查找: Local => Enclosing => Global => Built-in
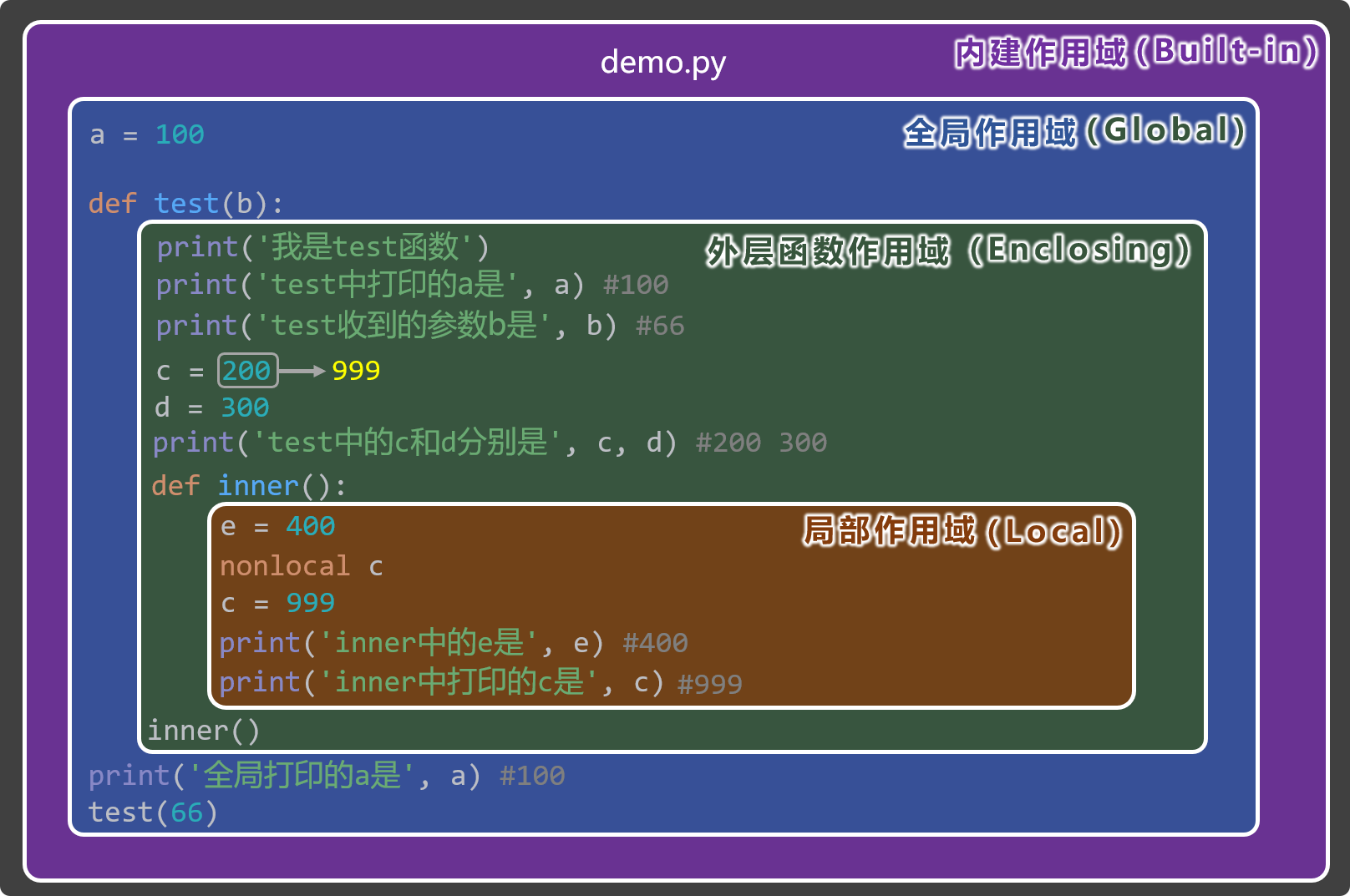
Python 中 global 和 nonlocal 语句的作用就是在内部作用域中,修改定义在外层作用域/全局作用域中的变量:
nonlocal语句用于在嵌套函数中,修改其外层函数作用域中的变量。它会修改直接外层的变量,但不会查找到全局作用域,如果外层没有,会报错SyntaxError。global语句用于在函数内部修改定义在模块全局(Global Scope)的变量。如果只是读取全局变量,不需要global。如果要在函数内部赋值/修改全局变量,必须使用global声明。
# 访问外层变量不用`nonlocal`,修改外层变量时要使用`nonlocal`。
def outer():
y = 20 # outer 的局部变量 → inner 的 Enclosing 变量
z = 10
def inner():
print(y) # 内层函数读取外层变量
nonlocal z
z = 99 # 内层函数修改外层变量
print(z)
inner()a = 100 # 全局变量
b = 100
def test():
print(a) # 可以读取
global b
b = 200 # 修改全局变量闭包
闭包 = 内层函数 + 被内层函数引用的外层变量。
产生闭包的三个条件如下:
- 必须有函数嵌套
- 内层函数使用了外层函数的变量
- 外层函数返回内层函数
def outer():
num = 10
def inner():
nonlocal num
num += 1
print(num)
return inner
f = outer()
f() # 11
f() # 12
f() # 13
# outer函数中,被inner所使用到的那些变量,会被封存到【闭包单元(cell)】中。
# 这些 cell 会组成一个 __closure__ 元组,最终放在了 inner 函数身上。
# 打印 __closure__ 元组
print(f.__closure__) # (<cell at 0x7f29e25c2860: int object at 0x55e516f43430>,)
# 打印 __closure__ 元组中的某一项的具体值
print(f.__closure__[0].cell_contents) # 13闭包之间是互相独立的:
- 每次获得一个新闭包,互不影响。调用n次外层函数,就会得到n个不同的闭包,
- 外层变量为可变对象时仍互不影响。
def outer():
nums = []
def inner(value):
nums.append(value)
print(nums)
return inner
f1 = outer()
f1(10) # [10]
f1(20) # [10, 20]
f1(30) # [10, 20, 30]
f2 = outer()
f2(666) # [666][!info] 闭包的优点
- 可以“记住”状态:不用全局变量,也不用写类,就能在多次调用之间保存数据。
- 可以做“配置过的函数”:先传一部分参数,把环境固定住,得到一个定制版函数。
- 可以实现简单的“数据隐藏”:外层变量对外不可见,只能通过内层函数访问。
- 是装饰器(decorator)等高级用法的基础。
[!warning] 闭包的缺点
- 如果闭包里引用了很大的对象,又长期不释放,可能会增加内存占用。
- 很多场景下,其实用【类 + 实例属性】会更清晰,闭包不一定是最优解。
装饰器
装饰器是一种在【不修改原函数代码】的前提下,对函数进行【增强】的工具。 它是 Python 中非常强大的语法特性,常用于:日志、校验、计时、缓存、权限控制等。
装饰器是一种可调用对象(通常是函数),接收一个函数作为参数,并返回一个新函数。
函数装饰器
定义装饰器核心规则:
- 接收被装饰的函数、同时返回新函数(wrapper)
- 装饰器“吐出来”的是 wrapper 函数,以后别人调用的也是 wrapper 函数。
- 为了保证参数的兼容性,wrapper 函数要通过
*args和**kwargs接收参数。 - wrapper 函数中主要做的是:调用原函数(被装饰的函数)、执行其它逻辑,但要记得将原函数的返回值 return 出去。
# 定义函数装饰器
def say_hello(func):
def wrapper(*args, **kwargs):
print('你好,我要开始计算了')
return func(*args, **kwargs)
return wrapper
# 调用say_hello装饰器,对add函数进行装饰,并得到装饰后的新函数
# 使用语法糖 @ 等价于手动装饰:
# add = say_hello(add)
# result = add(10, 20, 30)
@say_hello
def add(x, y, z):
res = x + y + z
print(f'{x}和{y}和{z}相加的结果是:{res}')
return res
result1 = add(10, 20, 30)
print(result1)
'''
你好,我要开始计算了
10和20和30相加的结果是:60
60
'''
@say_hello会自动执行:add = say_hello(add)。以后调用add()时,真正执行的是wrapper()。
多个函数装饰器一起使用,距离函数最近的装饰器,会先工作。
带参数的函数装饰器(三层嵌套):外层接收配置、中间层接收函数、内层接收具体参数。
def say_hello(msg):
def outer(func):
def wrapper(*args, **kwargs):
print(f'你好,我要开始{msg}计算了')
return func(*args, **kwargs)
return wrapper
return outer
# 装饰加法函数
@say_hello('加法')
def add(x, y, z):
res = x + y + z
print(f'{x}和{y}和{z}相加的结果是:{res}')
return res
# 装饰减法函数
@say_hello('减法')
def sub(x, y):
res = x - y
print(f'{x}和{y}相减的结果是:{res}')
return res
# 测试代码
result1 = add(10, 20, 30)
result2 = sub(20, 10)类装饰器
包含__call__方法的类,就是类装饰器。
- 像调用函数一样,去调用类装饰器的实例对象,就会触发
__call__方法的调用。 __call__方法通常接收一个函数作为参数,并且会返回一个新函数。
class SayHello:
def __call__(self, func):
def wrapper(*args, **kwargs):
print('你好,我要开始计算了')
return func(*args, **kwargs)
return wrap带参数的类装饰器写起来,要比带参数的函数装饰器简单,不需要三层嵌套结构。
``per
@SayHello() # 类名后要加圆括号调用
def add(x, y):
res = x + y
print(f'{x}和{y}相加的结果是{res}')
return res
# 使用 SayHello 去装饰 add 函数(手动装饰)
# say = SayHello()
# add = say(add)
# result = add(10, 20)
# 通过`语法糖@`使用装饰器
result = add(10, 20)带参数的类装饰器写起来,要比带参数的函数装饰器简单,不需要三层嵌套结构。
class SayHello:
def __init__(self, msg):
self.msg = msg
def __call__(self, func):
def wrapper(*args, **kwargs):
print(f'你好,我要开始{self.msg}计算了')
return func(*args, **kwargs)
return wrapper
@SayHello('加法')
def add(x, y):
res = x + y
print(f'{x}和{y}相加的结果是{res}')
return res
result = add(10, 20)``
多个类装饰器一起使用,和之前的函数装饰器一样,离函数近的装饰器,先工作。
类型注解
类型注解不会影响程序运行,它只是给人和工具看的,它可以提高代码可读性、让 IDE 智能提示更强 。
变量类型注解
语法格式:变量名: 类型 = 值。
num: int = 100
prcie: float = 12.5
message: str = '你好啊'
is_vip: bool = True
result: None = None # 语法上没有问题,但这么写没有意义
hobby: list[str] = ['抽烟', '喝酒', '烫头']
hobby: list[str | int] = ['抽烟', '喝酒', '烫头'] # 元素类型是str或int
citys: set[str] = {'北京', '上海', '深圳'}
citys: set[str | float | bool] = {'北京', '上海', '深圳'}
persons: dict[str, int] = {'张三': 18, '李四': 19, '王五': 20}
persons: dict[str | int, int] = {'张三': 18, '李四': 19, '王五': 20} # 键是 str 或 int 类型,值是 int 类型元组的类型注解有些特殊:
# scores 是元组,并且元组中仅包含1个int类型的元素
scores: tuple[int] = (60,)
# scores 是元组,并且元组中包含3个int类型的元素
scores: tuple[int, int, int] = (60, 70, 80)
# scores 是元组,并且元组中包含任意个数的元素,但每个元素的类型必须是int
scores: tuple[int, ...] = (60, 70, 80, 90, 100)
# scores 是元组,并且元组中包含任意个数的元素,每个元素的类型可以是:int 或 str
scores: tuple[int | str, ...] = (60, '70', 80, '90', 100)注意:可以先写变量的类型注解,以后再赋值。
# school: str并不是在定义变量,只是说明:如果未来有 school 变量,那应该是 str 类型。Python 执行到 school = '尚硅谷' 这句代码时,才会真正的定义 school 变量。
school: str
school = '尚硅谷'Python 中存在类型推导:根据变量初始赋值的实际数据,自动推断变量的类型。
- 对于非容器变量:后续如果改变类型,不会警告。
- 对于容器变量:要求内部元素类型必须与推导出来的一致,否则就会警告。
函数类型注解
函数类型注解:给函数的【参数】和【返回值】添加类型说明。语法格式:函数名(参数1: 类型, 参数2: 类型) -> 返回值类型:
# 给参数和返回值加类型注解
def add(x: int, y: int) -> int:
return x + y
# 带默认值的参数,可以不写注解
def add(x=1, y=1) -> int:
return x + y
# 设置多个返回值的类型注解
def show_nums_info(nums: list[int]) -> tuple[int, int, float]:
max_v = max(nums)
min_v = min(nums)
return max_v, min_v, max_v / min_v
# 可变参数类型注解
def add(*args: int) -> int:
return sum(args)
def show_info(**kwargs: str | int):
print(kwargs)
# 获取函数的注解信息
print(add.__annotations__)迭代器
[!info] 前置知识:可迭代对象(iterable)
能被 for 循环遍历(for item in iterable)的对象,就是可迭代对象
可迭代对象都有__iter__方法。
调用__iter__方法会得到:迭代器(iterator)。
__iter__是一个魔法方法,当调用iter函数时,__iter__会自动调用。可迭代对象.__iter__()等价于:iter(可迭代对象)。- 如果
iter(obj)能得到一个迭代器(iterator),那obj就是可迭代对象。
names = ['张三', '李四', '王五']
citys = ('北京', '上海', '深圳')
msg = 'hello'
print(names.__iter__())
print(citys.__iter__())
print(iter(msg))
'''
<list_iterator object at 0x7ff6a53819c0>
<tuple_iterator object at 0x7ff6a53819c0>
<str_ascii_iterator object at 0x7ff6a53819c0>
'''迭代器(iterator)拥有 __next__方法,每次调用都会根据当前的状态,返回下一个元素。
迭代器.__next__()等价于next(迭代器)。- 当所有元素全都取出后,若继续调用
__next__,Python会抛出StopIteration异常。
names = ['张三', '李四', '王五']
it = iter(names)
print(it.__next__()) # 张三
print(it.__next__()) # 李四
print(next(it)) # 王五
print(next(it)) # StopIteration,迭代器是一次性的,状态只会向前推进,且不会自动重置(迭代器在遍历的过程中会被“消耗”)。for循环遍历names列表背后的逻辑:
'''
names = ['张三', '李四', '王五']
for item in names:
print(item)
'''
names = ['张三', '李四', '王五']
# 调用【可迭代对象的__iter__方法】获取到一个迭代器(iterator)
it = iter(names)
# 开启一个无限循环
while True:
try:
# 调用__next__方法,获取下一个元素
item = next(it)
print(item)
except StopIteration:
# 捕获 StopIteration 异常,随后结束循环
break除了拥有
__next__方法,迭代器也拥有__iter__方法,并且其返回值是迭代器自身。
这么设计的原因:让 for 循环也能遍历迭代器(即:为了让iter(迭代器)不出错)。
至此,可以得出迭代器协议的全部内容,一个对象如果同时满足如下规范,那该对象就是一个迭代器:
- 能被
iter()接受。 - 能被
next()一步一步取值。
迭代器应用
需求:让for循环可以遍历Person的实例对象。
实现方式1:Person是可迭代对象,由 PersonIterator实现迭代器功能。
class Person:
def __init__(self, name, age, gender, address):
self.name = name
self.age = age
self.gender = gender
self.address = address
def __iter__(self):
return PersonIterator(self) # iter()每次调用会创建一个新迭代器
class PersonIterator:
def __init__(self, p):
# 将外部传进来的数据保存好
self.p = p
# 设置迭代器的初始化状态(指针位置)
self.index = 0
# 配置好要遍历的内容
self.attrs = [p.name, p.age, p.gender, p.address]
# 迭代器的__iter__方法会返回迭代器自身
def __iter__(self):
return self
# 每次调用__next__方法,会根据当前的状态,返回下一个元素
def __next__(self):
# 如果指针的位置超出范围,那就抛出StopIteration异常
if self.index >= len(self.attrs):
raise StopIteration
# 获取要返回的内容
value = self.attrs[self.index]
# 更新迭代器状态(指针位置)
self.index += 1
# 返回value
return value
p1 = Person('张三', 18, '男', '北京昌平')
for item in p1:
print(item)
for item in p1:
print(item)实现方式2:Person既是可迭代对象,又是迭代器。
class Person:
def __init__(self, name, age, gender, address):
self.name = name
self.age = age
self.gender = gender
self.address = address
# 设置迭代器的初始化状态(指针位置)
self.__index = 0
# 配置好要遍历的内容
self.__attrs = [name, age, gender, address]
def __iter__(self):
self.__index = 0
return self # iter()每次调用是同一个Person实例,只是重置了迭代器指针位置
def __next__(self):
# 如果指针的位置超出范围,那就抛出StopIteration异常
if self.__index >= len(self.__attrs):
raise StopIteration
# 获取要返回的内容
value = self.__attrs[self.__index]
# 更新迭代器状态(指针位置)
self.__index += 1
# 返回value
return value
p1 = Person('张三', 18, '男', '北京昌平')
for item in p1:
print(item)
for item in p1:
print(item)迭代器优势
- 迭代器是惰性计算,不会一次性生成所有结果,所以能显著降低内存占用。
- 当数据量很大,不确定要用多少结果时,推荐使用迭代器。
生成器
[!info] 前置知识:生成器函数
函数体中如果出现了yield关键字,那该函数是『生成器函数』。
不管能否执行到yield所在的位置,只要函数中有yield,那该函数就是『生成器函数』。
调用『生成器函数』时,其函数体不会立刻执行,而是返回一个『生成器对象』。
def demo():
print('demo函数开始执行了')
print(100)
yield
a = 200
print(a)
# d是生成器,demo是生成器函数
d = demo()
print(d) # <generator object demo at 0x7f8e7c145a80>写在『生成器函数』中的代码,需要通过『生成器对象』来执行:
- 调用『生成器对象』的
__next__方法,会让『生成器函数』中的代码开始执行。 - 当『生成器函数』中的代码开始执行后,遇到
yield会“暂停”,并会记录“暂停”的位置。 - 后续调用
__next__方法时,都会从上一次“暂停”的位置,继续运行,直到再次遇到 yield。 - 遇到
return会抛出StopIteration异常,并将return后面的表达式,作为异常信息。 yield后面所写的表达式,会作为本次__next__方法的返回值。
def demo():
print('demo函数开始执行了')
print(100)
yield '我是第1个yield所返回的数据'
a = 200
print(a)
yield '我是第2个yield所返回的数据'
b = 300
print(b)
return '尚硅谷'
d = demo()
r1 = next(d)
print(r1)
r2 = next(d)
print(r2)
try:
next(d)
except StopIteration as e:
print(e)
'''
demo函数开始执行了
100
我是第1个yield所返回的数据
200
我是第2个yield所返回的数据
300
尚硅谷
'''生成器对象是一种特殊的迭代器(本质是通过yield自动实现了迭代器协议)。生成器的写法更为紧凑,因为它会自动创建 __iter__() 和 __next__() 方法。
d = demo()
# 验证:生成器对象d,和迭代器一样,也拥有:__iter__ 和 __next__ 方法
print(hasattr(d, '__iter__')) # True
print(hasattr(d, '__next__')) # True
# 验证:生成器对象的__iter__方法,和迭代器一样,返回的也是自身
result = iter(d)
print(result == d) # Trueyield from 能把一个『可迭代对象』里的东西依次 yield 出去(替代:for + yield)。
def demo():
nums = [10, 20, 30, 40]
# for num in nums:
# yield num
yield from nums生成器.send(值) 可以让生成器继续执行的同时,给上一次yield传值。
next只能取值,send既能取值,也能送值。- 第一次启动生成器,不能传值(或者说只能传 None 值)
def demo():
print('demo函数开始执行了')
print(100)
a = yield '我是第1个yield所返回的数据'
print(a)
b = yield '我是第2个yield所返回的数据'
print(b)
return '尚硅谷'
d = demo()
r1 = next(d) # 此处等价于 d.send(None)
print(r1)
r2 = d.send(666) # d中的a为 666
print(r2)
try:
d.send(888) # d中的b为 888
except StopIteration as e:
print(e)生成器应用
用生成器实现遍历Person类的实例对象:
class Person:
def __init__(self, name, age, gender, address):
self.name = name
self.age = age
self.gender = gender
self.address = address
self.__attr = [name, age, gender, address]
def __iter__(self):
# yield self.name
# yield self.age
# yield self.gender
# yield self.address
yield from self.__attr
p1 = Person('张三', 18, '男', '北京昌平')
for attr in p1:
print(attr)生成器表达式
生成器表达式:一种用类似列表推导式的语法,快速创建生成器对象的方式。相比等效的列表推导式则更为节省内存。
- 语法格式:
(表达式 for 变量 in 可迭代对象)。 - 什么时候适合用生成器表达式?当“每个结果,只依赖当前这一个元素”时。
nums = [10, 20, 30, 40]
# 列表推导式
result1 = [n * 2 for n in nums]
print(result1)
# 生成器表达式(和列表推导式很像,不要搞混)
result2 = (n * 2 for n in nums)
for item in result2:
print(item)第7章 错误和异常
- 错误:代码本身有语法错误,解释器无法执行代码。无法通过异常处理机制解决。
- 异常:代码在语法上没问题,但执行过程中出现了问题。可以通过异常处理机制解决。
Python 中异常类的继承关系(层级关系)如下:
BaseException
├── KeyboardInterrupt
├── SystemExit
└── Exception
└── ......
BaseException是所有异常类的父类,它的子类Exception中包含的是开发中常见的业务异常。
不是Exception的子类的异常通常不被处理,因为它们被用来指示程序应该终止,包括由sys.exit()引发的SystemExit,以及当用户希望中断程序时引发的KeyboardInterrupt。
异常处理
- 将可能出现异常的代码放在
try中,出现异常后的处理代码写在except中。- 如果
try中的代码出现异常,那try中的后续代码不会执行,并自动跳转到except中。 - 如果
try中的代码没有异常,那except中的代码就不会执行。
- 如果
- 无论是否发生异常,
try-except后面的代码都会继续执行。 - 可选:
else:如果一切顺利(没有异常出现)要做的事。finall:无论有没有异常,都要做的事。
print('欢迎使用本程序')
try:
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
result = a / b
print(f'{a}除以{b}的结果是:{result}')
# except: # 直接写`except`捕获到`Python`中所有的异常。实际开发中不推荐这样做。
# print('抱歉,程序出现了异常!')
except ZeroDivisionError:
print('程序异常:0不能作为除数!')
except ValueError:
print('程序异常:您输入的必须是数字!')
except Exception:
print('程序异常!')
else:
print('挺好的,try中的代码没有任何异常!')
finally:
print('无论有没有异常,我的计算都结束了!')
print('*******我是后续的其它逻辑1*******')
print('*******我是后续的其它逻辑2*******')获取异常的具体信息:通过e变量,可以获取异常相关的信息,也可以借助traceback去格式化异常信息。
print('欢迎使用本程序')
try:
a = int(input('请输入第一个数:'))
b = int(input('请输入第二个数:'))
print(x)
result = a / b
print(f'{a}除以{b}的结果是:{result}')
# 一个 except 捕获不同的异常
except (ZeroDivisionError, ValueError, Exception) as e:
if isinstance(e, ZeroDivisionError):
print('程序异常:0不能作为除数!')
elif isinstance(e, ValueError):
print('程序异常:您输入的必须是数字!')
else:
print(f'程序异常:{e}')
print('*******我是后续的其它逻辑1*******')
print('*******我是后续的其它逻辑2*******')手动抛出异常
当程序遇到不符合预期情况时,可以使用raise语句手动触发(抛出)异常。
print('欢迎使用年龄判断系统')
try:
age = int(input('请输入你的年龄:'))
if 18 <= age <= 120:
print('成年')
elif 0 <= age < 18:
print('未成年')
else:
# print('输入的年龄有误!(年龄应该为0~120的整数)')
raise ValueError('年龄应该为0~120的整数')
except Exception as e:
print(f'程序异常:{e}')为了表明一个异常是另一个异常的直接后果, raise 语句允许一个可选的 from 子句。比如下面代码中引起 RuntimeError 的直接原因是 exc ,即 ConnectionError。
def func():
raise ConnectionError
try:
func()
except ConnectionError as exc:
raise RuntimeError('Failed to open database') from exc
'''
ConnectionError
The above exception was the direct cause of the following exception:
RuntimeError: Failed to open database
'''使用 from None 表达禁用自动异常链,比如下面 OSError 的详细信息被隐藏了。
try:
open('database.sqlite')
except OSError:
raise RuntimeError("无法打开数据库") from None
'''
Traceback (most recent call last):
File "<stdin>", line 4, in <module>
RuntimeError: 无法打开数据库
'''[!info] 异常的传递机制
- 如果异常没有被当前代码块所捕获处理,那该异常就会沿着调用链,逐层传递给其调用者。
- 如果所有调用者,都没有捕获该异常,那最终程序将因【未处理异常】而意外终止。
异常也可以添加注释说明,就像用注释解释代码那样。异常有一个 add_note(note) 方法接受一个字符串,并将其添加到异常的注释列表。标准的回溯在异常之后按照它们被添加的顺序呈现包括所有的注释。
>>> try:
... raise TypeError('bad type')
... except Exception as e:
... e.add_note('Add some information')
... e.add_note('Add some more information')
... raise
...
Traceback (most recent call last):
File "<stdin>", line 2, in <module>
TypeError: bad type
Add some information
Add some more information自定义异常类
由开发人员自己定义一个异常类,用来表示代码中“更具体、更有业务含义”的异常。
具体规则:定义一个类(类名通常以Error结尾),继承Exception类或它的子类。
class SchoolNameError(Exception):
def __init__(self, msg):
super().__init__('【校名异常】' + msg)
def check_school_name(name):
if len(name) > 10:
raise SchoolNameError('学校名过长')
else:
print('学校名是合法的')
try:
check_school_name('atguiguuuuuuuuuuuuuuu')
except SchoolNameError as e:
print(f'程序异常:{e}') # 程序异常:【校名异常】学校名过长第8章 模块与包
模块
在 Python 中,一个.py文件就是一个模块(Module)。
- 模块中可以包含:变量、函数、类等很多内容。
- 通常把能够实现某一特定功能的代码,集中放在一个模块中(模块就类似于一个工具箱)。
- 模块可以提高代码的可维护性与可复用性,还可以避免命名冲突。
- 在模块内部,通过全局变量
__name__获取模块名。作为主程序直接运行,__name__的值是__main__。
Python 中的模块分为三类,分别是:标准库模块、自定义模块、第三方模块。
- 有一些标准库模块是用C语言实现的,这些用C语言实现的模块,又称:内置模块。
- 标准库模块保存在Python安装目录中的
Lib文件夹中(可以通过__file__查看文件位置),但内置模块无法在Lib中看到。 - 自定义模块不要与标准库模块同名(一旦同名,Python 会优先引入标准库模块)
导入模块的方式有:
1️⃣import 模块名
2️⃣import 模块名 as 别名
3️⃣from 模块名 import 具体内容1, 具体内容2, ......
4️⃣from 模块名 import 具体内容 as 别名
5️⃣from 模块名 import *在 Python 模块中,可通过 __all__ 来控制 from 模块 import * 能导入哪些内容。
# 订单最大金额
max_order_amount = 1000000
# 创建订单
def create_order():
print('订单创建成功!')
# 关闭订单
def cancel_order():
print('订单关闭成功!')
# 提示函数
def show_info():
print('我是来自【订单】模块的提示!')
# __all__ 的值可以是:列表、元组。
__all__ = ('create_order', 'cancel_order')为了快速加载模块,Python 把模块的编译版本缓存在
__pycache__目录中,文件名为module._version_.pyc。
从.pyc文件读取的程序不比从.py读取的执行速度快,.pyc文件只是加载速度更快。
Python 对比编译版与源码的修改日期,查看编译版是否已过期,是否要重新编译。此进程完全是自动的。此外,编译模块与平台无关,因此,可在不同架构的系统之间共享相同的库。
包
包与模块的关系:
- 一个模块就是一个
.py文件 ,包是用来“管理模块”的目录(文件夹)。 - 一个包中可以有多个模块,也可以有多个子包。
- 包目录需要创建一个
__init__.py文件。
[!info] 关于
__init__.py文件
__init__.py是包的初始化文件,在包被导入时,__init__.py会被自动调用__init__.py中可以编写一些包的初始化逻辑__init__.py中所定义的内容,会被from 包名 import *形式全部引入__init__.py中也可以使用__all__来控制包中的哪些模块可以被from 包名 import *引入
Python 中的包分为三类,分别是:标准库包、自定义包、第三方包。
导入包的方式有:
1️⃣import 包名.模块名
2️⃣import 包名.模块名 as 别名
3️⃣from 包名.模块名 import 具体内容1
4️⃣from 包名.模块名 import 具体内容 as 别名
5️⃣from 包名.模块名 import *
前五种方式,类似“导入模块的方式”
6️⃣from 包名 import 模块名
7️⃣from 包名 import 模块名 as 别名
8️⃣from 包名 import *
9️⃣import 包名注意:想通过import 包名形式进行导入入,就必须在__init__.py中定义好具体的内容。
# __init__.py
# 包设计为 import trade 然后 trade.order 的方式使用,需要 import 语句
import order
import pay
# 包设计为 from trade import * 的方式使用,需要 __all__
__all__ = ['order', 'pay']以上引入方式,都可以用于引入子包,只需要在包名的后面跟上子包名即可。
'''
└── trade/
└── hello/
├── __init__.py
└── h1.py
├── __init__.py
├── order.py
└── pay.py
└── demo.py
'''
# from 包名.模块名 import 具体内容1
from trade.hello.h1 import say_hello第三方包
PyPI 是是 Python 官方推荐、官方维护的包发布与分发平台(https://pypi.org)
pip是 Python 包管理工具,该工具提供了对 Python 包的查找、下载、安装、卸载的功能。默认的源是 PyPI。
| pip常用命令 | 说明 |
|---|---|
pip install 包名 | 安装指定的包。 |
pip install -i 镜像地址 包名 | 临时使用镜像地址安装指定包。 |
pip config set global.index-url 地址 | 设置 pip 所使用的镜像地址。 |
pip config list | 查看当前环境的 pip 配置。 |
pip config unset global.index-url | 让 pip 恢复使用官方默认的地址。 |
pip list | 列出当前环境中,已安装的所有第三方包。 |
pip uninstall 包名 | 从当前环境中卸载指定的第三方包。 |
Python环境
Python 环境分为两种,分别是全局环境(系统环境)、虚拟环境。
环境就是指:python 解释器 + 依赖包。
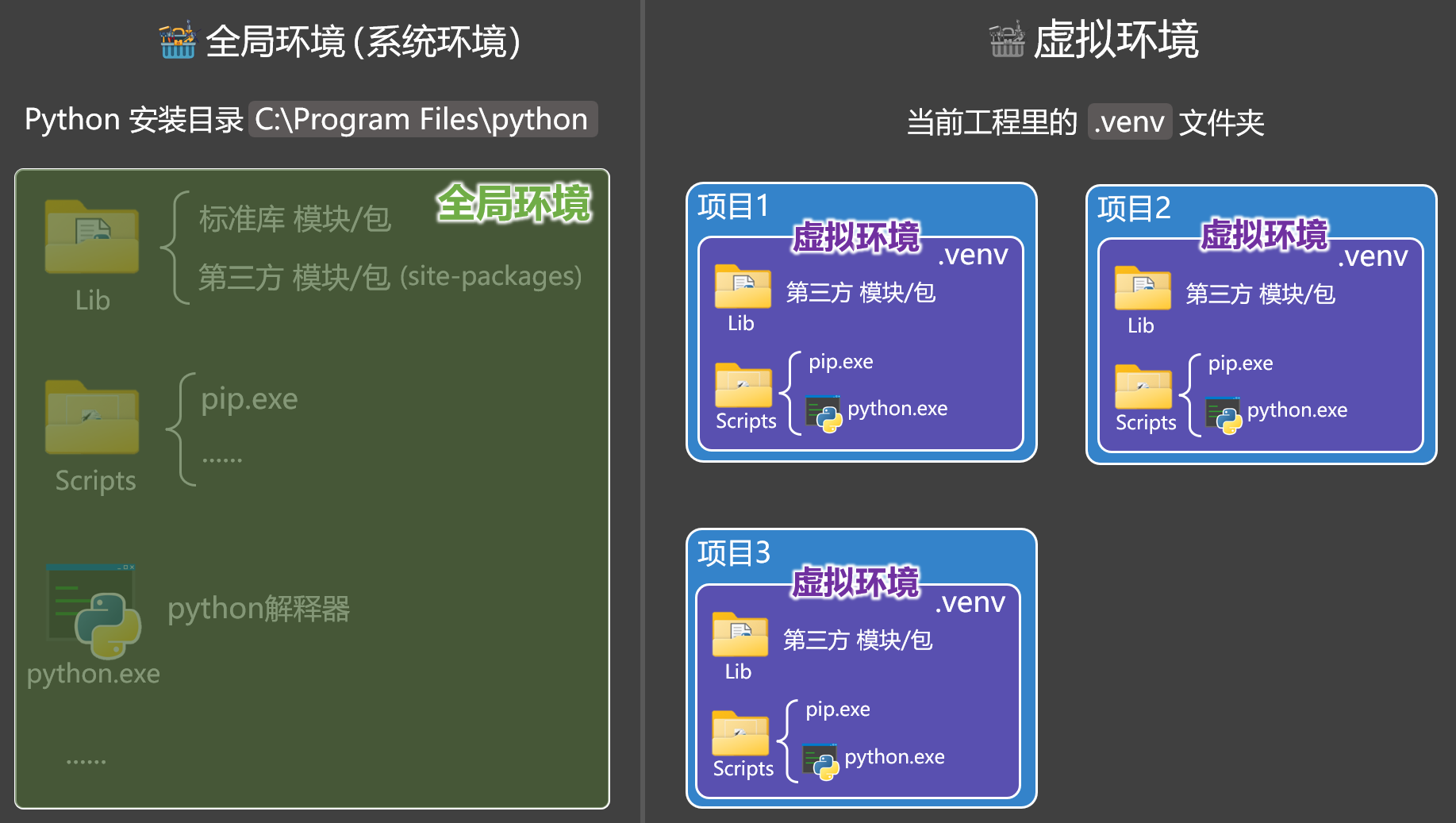
- 虚拟环境有自己独立的一套:Python 解释器、pip 命令、第三方依赖包,不和其它项目产生干扰。
- 虚拟环境和全局环境共用的东西,只有标准库。